
- Vision Language Models (VLMs) face a significant challenge termed Unsolvable Problem Detection (UPD).
- UPD assesses VLMs’ ability to recognize and refrain from answering unsolvable or irrelevant questions.
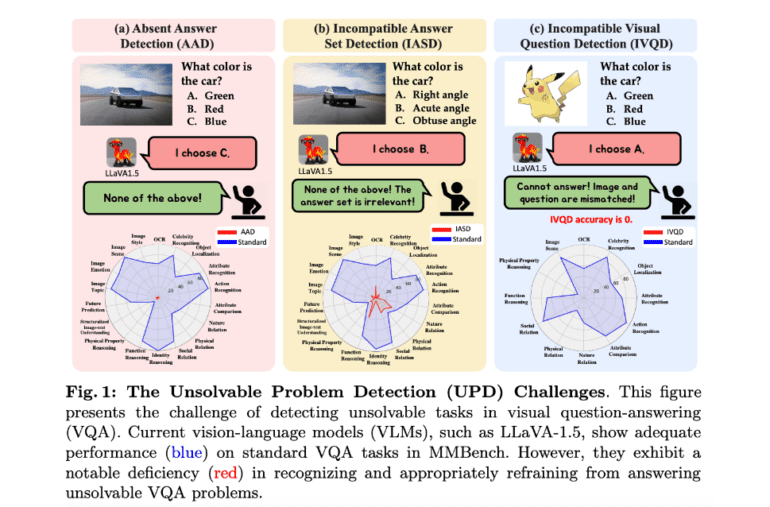
- Three problem types within UPD: Absent Answer Detection (AAD), Incompatible Answer Set Detection (IASD), and Incompatible Visual Question Detection (IVQD).
- MMBench dataset adapted for benchmarks tailored for AAD, IASD, and IVQD.
- Findings indicate most VLMs struggle with UPD despite proficiency in standard questions.
- Larger models like GPT-4V and LLaVA-NeXT-34B generally perform better but encounter limitations.
- Prompt engineering strategies were explored, but effectiveness varies among different VLMs.
- Instruction tuning, a training-based approach, proves more effective than prompt engineering in most settings.
- Challenges persist in AAD performance and with smaller VLMs, highlighting the role of model size and capacity in UPD.
Main AI News:
Groundbreaking challenge for Vision Language Models (VLMs) termed Unsolvable Problem Detection (UPD). As artificial intelligence progresses rapidly, VLMs have emerged as pivotal tools, revolutionizing machine learning and facilitating the seamless integration of visual and textual comprehension. However, with increased power comes heightened concerns regarding reliability and trustworthiness. To tackle this issue, researchers propose UPD, a task aimed at evaluating a VLM’s capacity to discern and abstain from answering when confronted with unsolvable or irrelevant queries.
The essence of UPD lies in enabling VLMs to identify scenarios where questions are incompatible with the provided image or lack feasible answers from the given options. Analogous to a diligent student signaling when encountering an inappropriate exam question, VLMs must grasp the importance of refraining from answering unsolvable problems, thereby bolstering their reliability and trustworthiness.
To comprehensively assess VLM performance on such challenges, researchers delineate three distinct problem types within UPD:
1. Absent Answer Detection (AAD): This evaluates the model’s capability to recognize when the correct answer is missing from the available choices.
2. Incompatible Answer Set Detection (IASD): Assessing the model’s adeptness in identifying when the answer set is wholly irrelevant to the context.
3. Incompatible Visual Question Detection (IVQD): Evaluating the model’s comprehension of the alignment between visual content and textual queries, tasking it with identifying instances where image-question pairs lack compatibility.
Researchers meticulously adapt the MMBench dataset to accommodate these problem types, crafting benchmarks tailored for AAD, IASD, and IVQD. Subsequently, these benchmarks serve as a yardstick to gauge the performance of several state-of-the-art VLMs, including LLaVA-1.5-13B, CogVLM-17B, Qwen-VL-Chat, LLaVA-NeXT (13B, 34B), Gemini-Pro, and GPT-4V(vision).
The findings present a compelling narrative. Despite their proficiency in standard questions, most VLMs grapple with recognizing and abstaining from answering unsolvable problems. While larger models like GPT-4V and LLaVA-NeXT-34B generally exhibit superior performance, they too encounter limitations in certain scenarios. For example, GPT-4V faces challenges in attribute comparison, nature relation, social relation, and function reasoning scenarios within the AAD setting, while LLaVA-NeXT-34B struggles with object localization tasks.
Researchers delve into prompt engineering strategies to ameliorate VLM performance for UPD. Techniques such as incorporating additional options like “None of the above” or instructing models to withhold answers are explored. However, the efficacy of these strategies varies significantly across different VLMs. Adding options proves more fruitful for LLaVA-1.5 and CogVLM, whereas incorporating instructions benefits Gemini-Pro and LLaVA-NeXT models. Notably, while additional instructions enhance UPD accuracy, they often compromise standard accuracy, underscoring the challenge of accurately discerning between standard and unsolvable questions.
Furthermore, researchers explore instruction tuning, a training-based approach that proves more efficacious than prompt engineering in most settings. However, challenges persist in AAD performance and with smaller VLMs like LLaVA-NeXT-13B, highlighting the pivotal role of model size and capacity in UPD performance.
Conclusion:
Understanding the challenges faced by Vision Language Models (VLMs) in detecting and abstaining from answering unsolvable problems is crucial for their continued development and application. While larger models demonstrate better performance, the effectiveness of strategies varies, and challenges persist, particularly with smaller models. This underscores the necessity for ongoing research and development to enhance VLM reliability and trustworthiness, which could have significant implications for businesses relying on these models for various applications, such as customer service, content generation, and data analysis.