
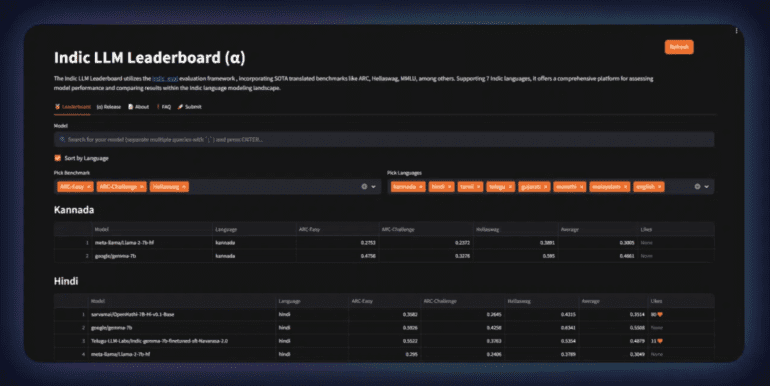
- CognitiveLab launches the Indic LLM Leaderboard, offering standardized evaluation for Indic Language Models.
- The Leaderboard supports 7 Indic languages with plans for additional benchmarks.
- Introduction of indic_eval framework for seamless evaluation score comparison.
- Deployment within India ensures data security.
- Ongoing enhancements promise a robust platform for model evaluation and comparison.
- Notable base models are already featured in the leaderboard.
- Divergence from Open LLM leaderboard with standardized evaluations.
- Utilization of translation APIs for accurate benchmarking across languages.
- The introduction of the Ambari series addresses the linguistic gap between Kannada and English.
Main AI News:
CognitiveLab has launched the inaugural Indic LLM Leaderboard, addressing the need for a standardized evaluation framework for the burgeoning field of Indic Language Models (LLMs). With the landscape witnessing a surge in Indic language models lacking a unified assessment platform, this release marks a significant milestone.
The Indic LLM Leaderboard encompasses evaluations across 7 prominent Indic languages: Hindi, Kannada, Tamil, Telugu, Malayalam, Marathi, and Gujarati, offering a comprehensive evaluation infrastructure. Hosted on the widely-used platform Hugging Face, it currently supports 4 Indic benchmarks, with plans for the integration of more benchmarks in subsequent updates.
Founder Adithya S Kolavi has also introduced indic_eval, an evaluation framework designed to complement the leaderboard. Supporting benchmarks such as Arc Easy, Challenge, Hellaswag, MMLU, BoolQ, and Translation, indic_eval streamlines the process of uploading and comparing evaluation scores seamlessly within the leaderboard environment.
Ensuring data security and privacy, this system is deployed entirely within India, bolstering confidence in the platform’s reliability. Despite being in its alpha stage, ongoing enhancements and rigorous testing promise a robust and evolving platform.
The leaderboard already features prominent base models such as ‘meta-llama/Llama-2-7b-hf’ and ‘google/gemma-7b’, providing a reference point for comparison and evaluation. With a steadfast commitment to improvement, CognitiveLab envisions the Indic LLM Leaderboard as a pivotal instrument in the advancement of Indic Language Models.
Functionally, the leaderboard operates by executing indic_eval on selected models and transmitting the results to a secure server for storage. The Frontend Leaderboard then retrieves the latest models, benchmarks, and metadata from the database, ensuring users access the most relevant information for comparison.
Diverging from the Open LLM leaderboard, this project introduces standardized evaluations utilizing common benchmarks due to computational constraints. Users are empowered to conduct evaluations on their GPUs, while the leaderboard serves as a centralized hub for model assessment and comparison.
To guarantee the accuracy and consistency of results, CognitiveLab leverages indictrans2 from AI4Bharat and other translation APIs to translate benchmarking datasets into the seven supported Indian languages.
In addition to the leaderboard initiative, CognitiveLab recently unveiled Ambari, an open-source Bilingual Kannada-English LLMs series. This endeavor aims to bridge the linguistic gap between Kannada and English, addressing the evolving needs of language modeling in a dynamic linguistic landscape.
Conclusion:
CognitiveLab’s introduction of the Indic LLM Leaderboard and indic_eval framework represents a significant advancement in the evaluation of Indic Language Models. By providing a standardized platform for comparison and assessment, CognitiveLab aims to facilitate the development and adoption of high-quality Indic Language Models, potentially revolutionizing the market by fostering innovation and efficiency in language technology.