
- Google DeepMind, in collaboration with McGill University and Mila, introduces Mixture-of-Depths (MoD) as a novel method for optimizing transformer models.
- MoD enables transformers to dynamically allocate computational resources, focusing on critical tokens within input sequences.
- This approach represents a paradigm shift in resource management, promising substantial efficiency gains without compromising performance.
- MoD-equipped models demonstrate comparable performance to traditional transformers while requiring up to 50% fewer floating-point operations per forward pass.
- In select scenarios, MoD-equipped models operate up to 60% faster, showcasing their potential to enhance efficiency in AI applications.
Main AI News:
The transformative potential of transformer models in AI, particularly in domains like language processing and machine translation, is well-documented. However, traditional approaches to computational resource allocation often overlook the intricate variations within input sequences, leading to suboptimal efficiency.
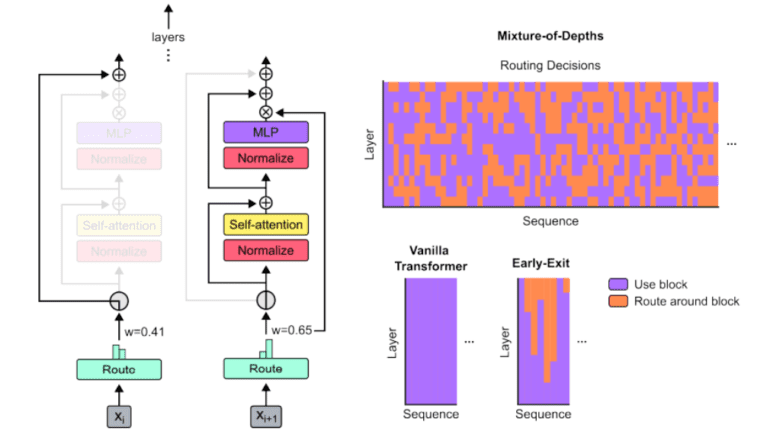
In response to this challenge, a collaborative endeavor involving Google DeepMind, McGill University, and Mila has yielded Mixture-of-Depths (MoD), a novel solution that diverges from conventional resource allocation strategies. By dynamically distributing computational resources, MoD enables transformers to prioritize critical tokens within sequences, ushering in a new era of efficiency and sustainability.
Key to MoD’s effectiveness is its ability to adapt computational focus within transformer models in real-time. Through a carefully crafted routing mechanism, MoD strategically allocates resources to tokens deemed essential for task completion, optimizing performance within a predefined computational budget.
Empirical evaluations demonstrate that MoD-equipped models maintain performance parity with traditional transformers while operating with significantly reduced computational overhead. Notably, these models achieve training objectives with comparable Flops but consume up to 50% fewer Flops per forward pass. In specific training scenarios, they exhibit up to 60% faster processing speeds, underscoring MoD’s potential to enhance efficiency without compromising quality.
Conclusion:
The introduction of Mixture-of-Depths (MoD) marks a significant advancement in the field of transformer models, promising improved computational efficiency without sacrificing performance. This innovation has the potential to reshape the AI market by enabling more efficient utilization of computational resources, ultimately leading to cost savings and accelerated development of AI applications. Businesses leveraging MoD-equipped models can expect to achieve their objectives with reduced computational overhead, gaining a competitive edge in the rapidly evolving landscape of AI technologies.