
- Transformers have revolutionized NLP, facilitating the development of highly accurate and fluent Large Language Models (LLMs).
- Transformer architecture, introduced in 2017, relies on attention mechanisms to comprehend long-range dependencies and contextual relationships in human language.
- Transformers consist of encoders and decoders, enabling context-rich representation and coherent text generation.
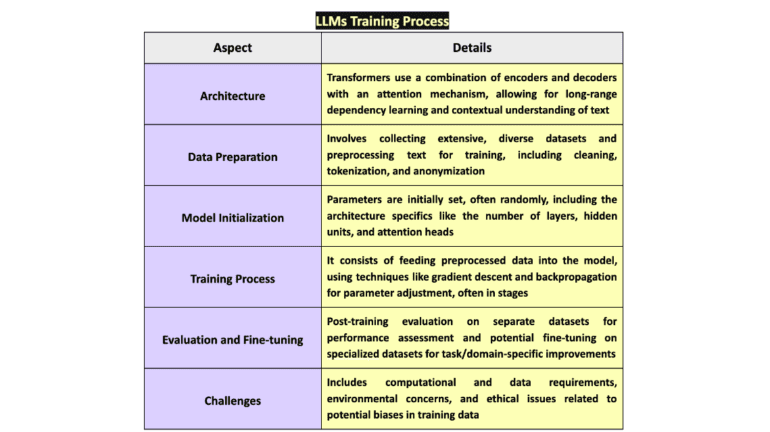
- Training LLMs involves data preparation, model initialization, iterative training processes, evaluation, and fine-tuning.
- Challenges include computational demands, data requirements, and ethical considerations regarding bias in training data.
Main AI News:
Transformers have significantly reshaped the landscape of Natural Language Processing (NLP) in recent years, epitomized by the emergence of LLMs such as OpenAI’s GPT series, BERT, Claude Series, and others. The advent of transformer architecture has ushered in a new era, enabling the development of models that comprehend and produce human language with unparalleled precision and coherence. Let’s explore the pivotal role that transformers play in NLP and elucidate the intricacies of training LLMs utilizing this groundbreaking architecture.
Understanding the Essence of Transformers
Introduced in the seminal research paper “Attention is All You Need” by Vaswani et al. in 2017, the transformer model represents a departure from the traditional reliance on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) for processing sequential data. At the heart of the transformer lies the attention mechanism, empowering the model to assess the significance of different words within a sentence irrespective of their positional proximity. This capability to grasp long-range dependencies and contextual associations between words is fundamental for deciphering the nuances of human language.
Transformers comprise two core components:
- Encoder
- Decoder
The encoder assimilates the input text and constructs a contextually rich representation thereof. Subsequently, the decoder utilizes this representation to generate the output text. Within this framework, a self-attention mechanism enables each position in the encoder to attend to all positions in the preceding layer of the encoder. Likewise, in the decoder, attention mechanisms facilitate focusing on distinct segments of the input sequence and the previously generated output, thereby fostering more cohesive and contextually apt text generation.
Training Large Language Models: A Comprehensive Overview
The training of LLMs entails multiple stages, ranging from data preparation to fine-tuning, necessitating extensive computational resources and datasets. Here’s an overview of the process:
- Data Preparation and Preprocessing: The initial step involves gathering a diverse and comprehensive dataset, typically encompassing text from various sources such as books, articles, websites, etc. Subsequently, the text data undergoes preprocessing, encompassing tasks such as cleaning, tokenization, and potentially anonymization to eliminate sensitive information.
- Model Initialization: Before commencing training, the model parameters are initialized, often randomly. This encompasses initializing the weights of neural network layers and attention mechanism parameters. The model’s size, layer count, hidden units, attention heads, etc., are determined based on task complexity and available training data.
- Training Process: Training involves feeding preprocessed text data into the model and iteratively adjusting parameters to minimize disparities between the model’s output and the expected output. While supervised learning is employed for specific output-oriented tasks like translation or summarization, many LLMs leverage unsupervised learning, where the model predicts the next word in the sequence based on preceding words.
- Evaluation and Fine-tuning: Post-training, the model undergoes evaluation using a separate dataset to assess performance and identify areas for enhancement. Subsequently, fine-tuning may be undertaken, involving additional training on a specialized dataset to tailor the model to specific tasks or domains.
- Challenges and Considerations: Significant computational and data requirements pose challenges concerning environmental impact and accessibility for researchers with limited resources. Ethical considerations also arise due to the potential bias present in training data, which can be learned and perpetuated by the model.
Large language models trained using transformer architecture have established new benchmarks for machine comprehension and human language generation, driving advancements in translation, summarization, question-answering, and beyond. As research progresses, further enhancements in model efficiency and effectiveness can be anticipated, expanding their utility while mitigating inherent limitations.
Conclusion:
The adoption of transformer technology in NLP has significantly enhanced the capabilities of Large Language Models, driving advancements in various applications such as translation and question-answering. However, the market must address challenges related to computational resources, data accessibility, and ethical concerns to fully capitalize on the potential of these innovations. Investing in research and development to overcome these hurdles will pave the way for broader utilization and integration of transformer-based models across industries.