
- Pretrained language models often require fine-tuning for specific tasks.
- Conventional fine-tuning methods can be resource-intensive.
- Stanford researchers propose Representation Finetuning (ReFT) methods.
- ReFT focuses on manipulating model representations instead of weights.
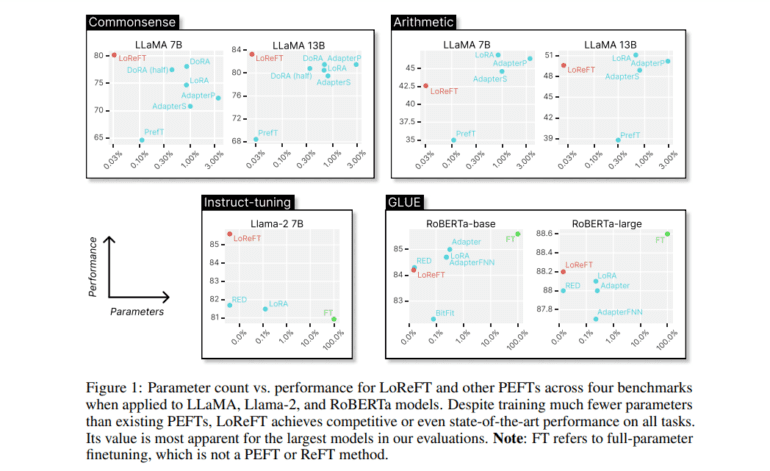
- Low-rank Linear Subspace ReFT (LoReFT) shows promising results with fewer parameters.
- Future research directions include exploring ReFT across different model families and domains.
Main AI News:
In the realm of natural language processing, pretrained language models (LMs) have become indispensable tools, routinely fine-tuned to suit specific domains or tasks. However, conventional fine-tuning approaches can be cost-prohibitive, particularly for large-scale models. To address this challenge, parameter-efficient fine-tuning (PEFT) methods have emerged, aiming to minimize memory usage and training time by updating only a fraction of the model’s weights.
Among PEFT techniques, adapters stand out as a popular choice. These modifications, which can be applied to a subset of the model’s weights or operate alongside the frozen base model, offer a promising avenue for efficiency gains. Recent advancements such as LoRA have further enhanced PEFT approaches by leveraging low-rank approximations during adapter training, effectively reducing the number of trainable parameters.
However, existing PEFT methods predominantly focus on weight modifications, overlooking the potential of fine-tuning representations directly. Recognizing the rich semantic information encoded in representations, researchers from Stanford University and Pr(Ai)2R Group have introduced Representation Finetuning (ReFT) methods.
In contrast to conventional fine-tuning techniques, ReFT methods eschew weight adjustments in favor of training interventions that manipulate a small subset of model representations. This innovative approach, inspired by recent strides in LM interpretability research, aims to steer model behaviors towards solving downstream tasks during inference.
A notable member of the ReFT family is the Low-rank Linear Subspace ReFT (LoReFT). Operating within the linear subspace spanned by a low-rank projection matrix, LoReFT demonstrates exceptional performance on various benchmarks while utilizing significantly fewer parameters compared to traditional PEFT methods. These findings underscore the potential of ReFT methods as more efficient and effective alternatives in model adaptation.
Looking ahead, the research agenda for ReFT includes exploring its applicability across different model families and domains, particularly in the realm of vision-language models. Automating hyperparameter search and identifying more effective interventions for specific tasks are also key areas of interest. Moreover, investigating the efficacy of learned orthogonal subspaces promises to unlock further insights into model interpretability.
To ensure rigorous evaluation, it is imperative to establish standardized benchmarks for comparing PEFTs and ReFTs. This includes adopting compute- or time-matched hyperparameter-tuning protocols and guarding against overfitting by disallowing tuning or model selection based solely on the test set. By adhering to robust evaluation practices, researchers can ensure the real-world effectiveness of these model adaptation techniques.
Conclusion:
Stanford’s ReFT methods represent a significant advancement in the field of model adaptation, offering a more efficient alternative to conventional fine-tuning approaches. With the potential to reduce resource requirements while maintaining or even improving performance, these methods are poised to reshape how organizations approach model customization and deployment in various industries. Companies that adopt ReFT techniques can benefit from faster, more cost-effective model adaptation, gaining a competitive edge in rapidly evolving markets driven by AI technologies.