
- Recent research explores the correlation between compression and intelligence in AI.
- Large Language Models (LLMs) are at the forefront of this investigation, with language modeling viewed as a form of compression.
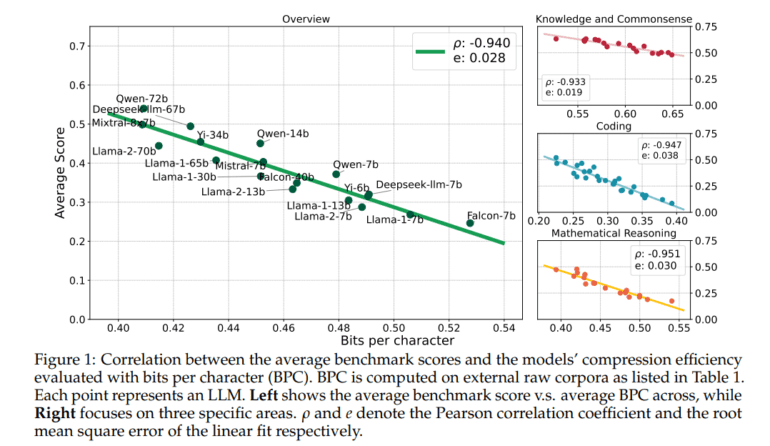
- Empirical evidence from a study by Tencent and The Hong Kong University of Science and Technology suggests a linear relationship between compression efficiency and downstream intelligence abilities of LLMs.
- Compression efficiency emerges as a robust metric for assessing LLMs’ capabilities, facilitating updates of text corpora and preventing overfitting.
- The study’s findings inspire further exploration into the link between compression and intelligence in AI, opening up new avenues for research.
Main AI News:
Cutting-edge developments in AI technology have sparked considerable interest in the relationship between compression and intelligence. The latest breakthroughs in Large Language Models (LLMs) have amplified this discourse, prompting a closer examination of language modeling through the lens of compression. Theoretical discussions posit that compression can effectively transform any prediction model into a lossless compressor and vice versa. Given the demonstrated efficacy of LLMs in data compression, it’s plausible to perceive language modeling as a form of compression.
In the current AI landscape dominated by LLMs, the argument for compression fostering intelligence gains traction. However, despite extensive theoretical deliberations, empirical evidence establishing a causal connection between compression and intelligence remains scarce. Addressing this gap, a pioneering study by Tencent and The Hong Kong University of Science and Technology ventures to empirically investigate this intriguing nexus.
The study adopts a pragmatic approach to defining “intelligence,” focusing on the model’s proficiency in various downstream tasks rather than engaging in abstract philosophical debates. Three core abilities—knowledge and common sense, coding, and mathematical reasoning—are employed as metrics to evaluate intelligence.
Methodically, the research team assesses the performance of diverse LLMs in compressing external raw corpora within specific domains, such as GitHub code, to evaluate coding skills. Subsequently, they utilize average benchmark scores to gauge the domain-specific intelligence of these models before subjecting them to a battery of downstream tasks.
The findings of the study, drawn from analyses involving 30 public LLMs and 12 distinct benchmarks, are striking: there exists a linear relationship between the downstream ability of LLMs and their compression efficiency, with a Pearson correlation coefficient nearing -0.95 for each intelligence domain examined. This linear association holds true across most individual benchmarks, even within the same model series characterized by shared configurations.
Remarkably, irrespective of factors like model size, tokenizer, or pre-training data distribution, the study presents compelling evidence that intelligence in LLMs correlates linearly with compression efficiency. This empirical validation lends credence to the longstanding conjecture that superior compression quality signifies higher intelligence, establishing a universal principle of linear association between the two variables.
Moreover, the study underscores the utility of compression efficiency as an unsupervised parameter for LLMs, enabling seamless updates of text corpora to mitigate overfitting and test contamination risks. Given its robust linear correlation with the models’ capabilities, compression efficiency emerges as a dependable metric for assessing LLMs.
To facilitate future academic endeavors in data gathering and updating compression corpora, the research team has generously shared their data collection and processing pipelines as open-source resources.
While the study acknowledges certain limitations, such as the exclusion of fine-tuned models and potential applicability issues to partially trained models, it paves the way for further exploration. By shedding light on the intricate interplay between compression and intelligence in AI, this research beckons the scientific community to delve deeper into this fertile domain, promising exciting avenues for future investigations.
Conclusion:
The research showcasing the linear relationship between compression efficiency and intelligence in LLMs holds significant implications for the AI market. Companies investing in AI development can leverage compression as a metric to gauge the intelligence of their models more accurately. Moreover, the validation of compression efficiency as a reliable parameter underscores its importance in optimizing AI performance, offering companies a competitive edge in delivering more intelligent AI solutions. This underscores the importance of continued research into the compression-intelligence nexus, driving innovation and advancement in the AI market.