
- Google’s Graph Mining team introduces TeraHAC algorithm for clustering massive datasets with trillion-edge graphs.
- Traditional clustering methods face scalability issues due to high computational costs and limitations.
- TeraHAC utilizes MapReduce-style algorithms to achieve scalability while maintaining high-quality clustering.
- The algorithm operates in rounds, partitioning graphs into subgraphs and performing merges based on local information.
- TeraHAC outperforms existing scalable clustering algorithms in precision-recall tradeoffs, making it ideal for large-scale graph clustering tasks.
Main AI News:
In the realm of graph mining, Google Research’s Graph Mining team has unveiled TeraHAC, a groundbreaking solution tailored to tackle the daunting challenge of clustering massive datasets brimming with hundreds of billions of data points. TeraHAC’s primary focus lies in handling trillion-edge graphs, which are pervasive in tasks such as prediction and information retrieval. These graph clustering algorithms are instrumental in amalgamating similar entities into coherent groups, thereby fostering a deeper comprehension of data relationships. However, conventional clustering methodologies grapple with the sheer scale of such datasets, encountering hurdles like exorbitant computational expenses and constraints in parallel processing. Undeterred by these obstacles, researchers have set out to conquer these challenges by pioneering a scalable and top-tier clustering algorithm.
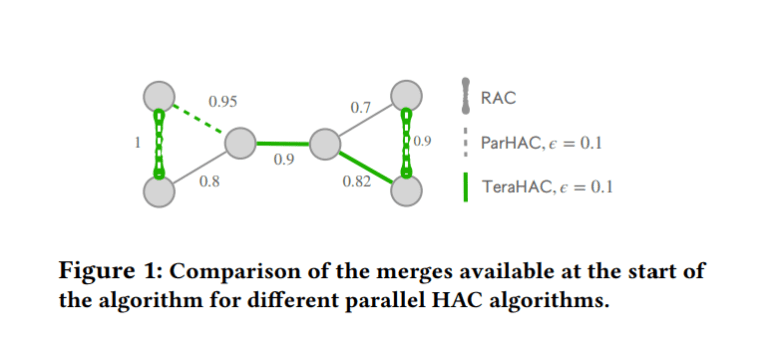
While prior techniques such as affinity clustering and hierarchical agglomerative clustering (HAC) have demonstrated efficacy, they confront limitations in scalability and computational efficacy. Affinity clustering, though scalable, may yield erroneous merges attributable to chaining, consequently yielding suboptimal clustering outcomes. Conversely, HAC proffers high-quality clustering but is plagued by quadratic complexity, rendering it unfeasible for trillion-edge graphs. Enter TeraHAC (Hierarchical Agglomerative Clustering of Trillion-Edge Graphs), a novel methodology underpinned by MapReduce-style algorithms, engineered to uphold scalability while delivering stellar clustering results. By dissecting the graph into subgraphs and executing merges predicated solely on local insights, TeraHAC surmounts the scalability predicament sans compromising on clustering excellence.
TeraHAC orchestrates its operations in iterative rounds, wherein each round entails the segmentation of the graph into subgraphs, followed by autonomous merges within each subgraph. The crux of this approach lies in identifying merges leveraging only local data within subgraphs, thereby ensuring that the ultimate clustering outcome closely mirrors that of a conventional HAC algorithm. This ingenious strategy empowers TeraHAC to scale seamlessly to trillion-edge graphs while markedly curtailing computational complexities vis-à-vis antecedent methods. Empirical evidence underscores TeraHAC’s prowess in computing high-caliber clustering solutions for gargantuan datasets housing several trillion edges, all accomplished within a day’s timeframe and leveraging modest computational resources. TeraHAC eclipses extant scalable clustering algorithms in terms of precision-recall tradeoffs, positioning it as the preeminent choice for large-scale graph clustering endeavors.
Conclusion:
Google’s unveiling of the TeraHAC algorithm marks a significant breakthrough in the realm of data analysis. By addressing the longstanding challenge of scaling clustering methodologies to trillion-edge graphs, TeraHAC opens up new possibilities for businesses and researchers dealing with massive datasets. Its ability to deliver high-quality clustering results within a reasonable timeframe using modest computational resources positions it as a game-changer in the market, offering unparalleled efficiency and accuracy in large-scale graph analysis tasks.