
- Unstructured framework addresses challenges in NLP data preprocessing before tokenization.
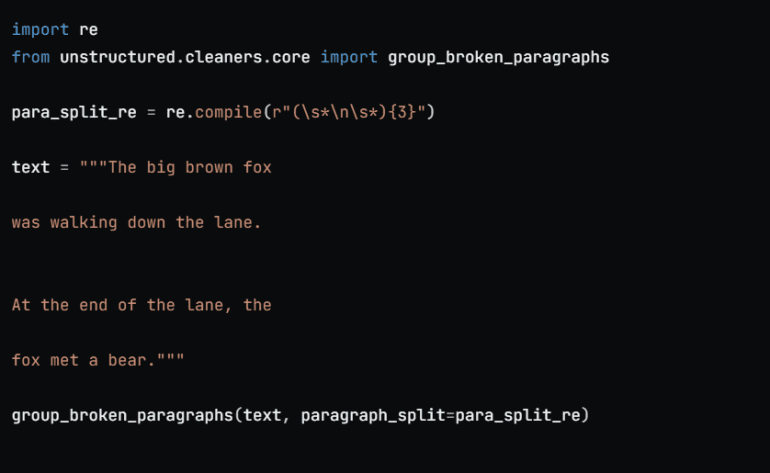
- Specialized cleaning operations refine text output, ensuring accurate tokenization.
- Offers extraction and transformation of diverse data types into LLM-friendly formats.
- Key features include document extraction, comprehensive file support, partitioning, cleansing, entity extraction, and high-performance connectors.
Main AI News:
In the realm of Natural Language Processing (NLP), the initial cleansing of data holds paramount importance, particularly in scenarios involving text data featuring unconventional word separations like underscores, slashes, or symbols instead of spaces. Given that conventional tokenizers heavily rely on spaces for text segmentation, this issue poses a significant challenge to the tokenization process.
This predicament underscores the critical need for a specialized framework or toolkit designed to effectively preprocess such data. Ensuring proper word segmentation prior to input into NLP models entails a range of tasks, including addition, deletion, or modification of these symbols. Failing to address this preliminary phase could lead to inaccurate tokenization, thereby adversely affecting subsequent NLP tasks such as sentiment analysis, language modeling, or text classification.
Enter the Unstructured framework, offering a comprehensive solution by furnishing an array of cleaning operations precisely crafted to refine text output, thereby tackling the challenge of data cleansing before tokenization. Particularly invaluable when handling unstructured data from diverse sources such as HTML, PDFs, CSVs, PNGs, and more, its capabilities shine in resolving formatting anomalies like unusual symbols or word separations, commonly encountered in such datasets.
Unstructured specializes in extracting and transforming intricate data into formats conducive to integration with Large Language Models (LLMs), such as JSON. With its versatility in handling various document types and layouts, data scientists can efficiently preprocess data at scale, unencumbered by formatting or cleansing hurdles.
Key features of the Unstructured framework, designed to streamline data workflows, include:
- Document Extraction: Unstructured excels in extracting metadata and document elements from a plethora of document formats, ensuring precise retrieval of relevant data for subsequent processing.
- Comprehensive File Support: Offering flexibility in managing diverse document formats, Unstructured ensures compatibility and adaptability across multiple platforms and use cases.
- Partitioning: Unstructured facilitates the extraction of structured content from unstructured texts through its partitioning capabilities. This function is instrumental in converting chaotic data into usable formats, thereby enhancing the efficiency of data processing and analysis.
- Data Cleansing: Equipped with robust cleaning capabilities, Unstructured ensures output sanitization, elimination of extraneous content, and optimization of NLP task performance by upholding data integrity, crucial in preparing data for NLP models.
- Entity Extraction: By pinpointing and isolating specific entities within documents, the platform’s extraction functionality simplifies data interpretation, focusing on pertinent information.
- Connectors: Unstructured offers high-performance connectors that streamline data workflows and cater to popular use cases such as Retrieval Augmented Generation (RAG), model fine-tuning, and pretraining. These connectors facilitate swift data import and export operations, enhancing overall workflow efficiency.
Now, with the Unstructured framework, embark on a journey towards seamless data preprocessing, ensuring optimal performance in your NLP endeavors.
Conclusion:
The emergence of Unstructured signifies a pivotal advancement in the NLP market, providing businesses with a powerful framework to address the complexities of data preprocessing before tokenization. By offering specialized cleaning operations and robust features for data extraction and transformation, Unstructured not only enhances the accuracy and efficiency of NLP tasks but also unlocks new opportunities for businesses to leverage the power of language models in various applications. This innovation underscores the growing demand for sophisticated NLP solutions tailored to meet the evolving needs of modern enterprises.