
- Text embedding models crucial in NLP for converting text into numerical data.
- Challenge: Enhance retrieval accuracy without escalating computational costs.
- Snowflake introduces Arctic-Embed models with data-centric training for superior efficiency.
- Methodology involves training on comprehensive datasets like MSMARCO and BEIR.
- Arctic-Embed models achieve outstanding nDCG@10 scores on MTEB Retrieval leaderboard.
Main AI News:
In the rapidly evolving landscape of natural language processing, text embedding models have emerged as indispensable tools. These models play a pivotal role in transforming textual data into a numerical format, enabling machines to comprehend, interpret, and manipulate human language with unprecedented accuracy. This technological innovation has far-reaching implications, empowering diverse applications ranging from search engines to conversational agents, thereby significantly augmenting operational efficiency and effectiveness. However, a persistent challenge in this domain lies in optimizing the retrieval accuracy of embedding models without incurring prohibitively high computational costs. Existing models often struggle to strike a balance between performance and resource utilization, necessitating a delicate equilibrium to ensure optimal outcomes.
Among the notable advancements in this field are the E5 model, renowned for its proficiency in processing web-crawled datasets, and the GTE model, which extends the applicability of text embedding through multi-stage contrastive learning methodologies. Additionally, frameworks like Jina specialize in handling lengthy documents, whereas variants of BERT, such as MiniLM and Nomic BERT, are tailored to address specific requirements such as efficiency and long-context data management. The integration of InfoNCE loss has significantly contributed to refining model training protocols, particularly concerning similarity-based tasks. Furthermore, the utilization of the FAISS library has streamlined document retrieval processes, optimizing the efficiency of embedding-driven search functionalities.
Snowflake Inc. has emerged as a trailblazer in this domain with the introduction of Arctic-Embed models, heralding a new era of efficiency and accuracy in text embedding technology. What sets these models apart is their adoption of a data-centric training approach, meticulously engineered to enhance retrieval performance without resorting to unwieldy increases in model complexity or size. Leveraging techniques such as in-batch negatives and a sophisticated data filtering mechanism, Arctic-Embed models have demonstrated unparalleled retrieval accuracy, positioning them as a pragmatic solution for real-world applications.
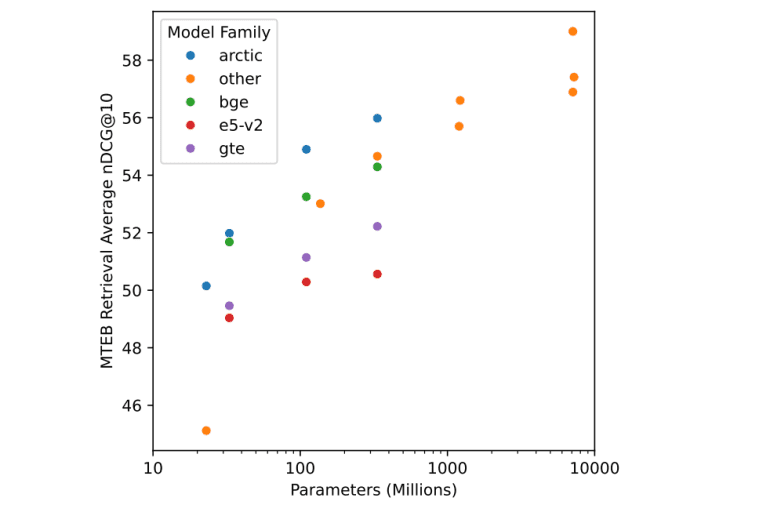
The methodology underpinning Arctic-Embed models revolves around rigorous training utilizing datasets such as MSMARCO and BEIR, renowned for their exhaustive coverage and benchmarking relevance within the field. Ranging from compact variants with 22 million parameters to expansive models boasting 334 million parameters, each iteration is meticulously calibrated to optimize key performance metrics such as nDCG@10 on the MTEB Retrieval leaderboard. These models leverage a blend of pre-trained language model architectures and fine-tuning strategies, including hard negative mining and streamlined batch processing, to elevate retrieval accuracy to unprecedented levels.
The performance of Arctic-Embed models on the MTEB Retrieval leaderboard speaks volumes about their efficacy. Notably, the nDCG@10 scores achieved by various models within this suite exhibit remarkable consistency, with the Arctic-Embed-l model attaining a pinnacle score of 88.13. This milestone underscores a significant leap forward compared to prior models, affirming the efficacy of the innovative methodologies embedded within these models. Indeed, these results underscore the capacity of Arctic-Embed models to tackle intricate retrieval tasks with unparalleled precision, thereby establishing a new benchmark in the realm of text embedding technology.
Conclusion:
The introduction of Arctic-Embed models by Snowflake signifies a significant advancement in text embedding technology, offering superior efficiency and accuracy in retrieval tasks. This innovation sets a new standard in the market, promising enhanced performance and scalability for applications across various industries, from search engines to conversational AI. Companies leveraging these models can expect improved operational efficiency and better user experiences, thereby gaining a competitive edge in the rapidly evolving landscape of natural language processing.