
- Tsinghua University researchers unveil attention offloading technique for LLM inference cost reduction.
- Attention offloading utilizes lower-priced GPUs for memory-intensive tasks, preserving high-cost accelerators for other operations.
- Heterogeneous architecture aligns resources with LLM inference demands, offering efficiency and cost-effectiveness.
- Lamina, a distributed heterogeneous LLM inference system, exemplifies attention offloading’s scalability and cost benefits.
- Empirical validation demonstrates Lamina’s superior throughput compared to existing solutions.
Main AI News:
In a recent breakthrough study from Tsinghua University, researchers have unveiled a groundbreaking technique that promises to reshape the economics of large language model (LLM) inference. Termed “attention offloading,” this innovative approach leverages strategic rearrangements of computations and hardware allocation, yielding substantial reductions in inference costs.
The core premise of attention offloading lies in its adept utilization of available resources, particularly in the realm of hardware. By strategically deploying lower-priced GPUs to handle memory-intensive operations, while reserving high-cost, compute-optimized accelerators for other tasks, companies can unlock significant efficiencies in LLM inference.
The Imperative for Efficiency in LLM Inference
As the demand for LLMs continues to surge, driven by applications spanning natural language processing to conversational AI, the necessity for cost-effective inference methodologies becomes paramount. Traditional approaches, reliant on homogeneous architectures of high-end accelerators, have proven financially burdensome and operationally suboptimal.
Unlocking the Power of Heterogeneous Architectures
Addressing this challenge, the research underscores the merits of adopting a heterogeneous architecture tailored to the distinctive demands of LLM inference. Unlike conventional methodologies that indiscriminately scale high-end flagship accelerators, the proposed approach advocates for a nuanced allocation of resources.
The Role of Attention Offloading in Driving Efficiency
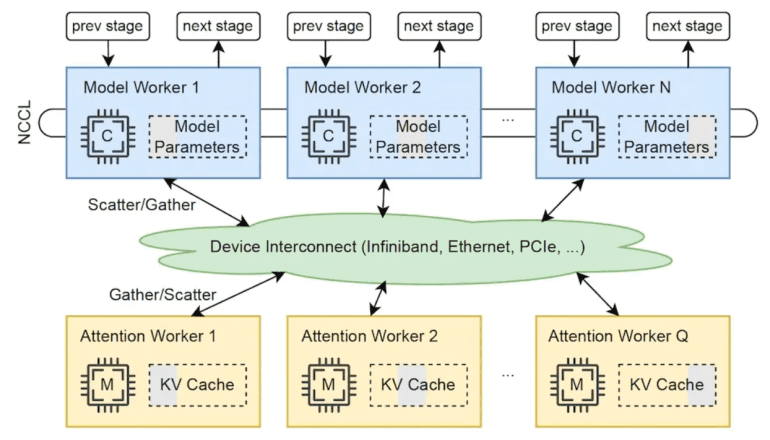
Central to this paradigm shift is the concept of attention offloading. By segregating accelerators into distinct pools optimized for computational power and memory bandwidth efficiency, organizations can strike an optimal balance between performance and cost-effectiveness.
In practical terms, attention computation, characterized by its high parallelizability, is delegated to low-cost, memory-efficient GPUs, while high-end accelerators are allocated to other critical operations. This strategic alignment of resources ensures that essential components—computational power, memory capacity, and bandwidth—are delivered in a synergistic and cost-efficient manner.
The Path Forward: Lamina – A Beacon of Innovation
Building upon these insights, the researchers introduce Lamina—a distributed heterogeneous LLM inference system embodying the principles of attention offloading. By harnessing consumer GPUs for attention computation and leveraging high-end accelerators for core inference tasks, Lamina achieves unprecedented scalability and cost-effectiveness.
Empirical Validation: Realizing Tangible Gains
Experimental validation demonstrates Lamina’s prowess, showcasing throughput gains ranging from 1.48X to 12.1X compared to existing solutions. With the ability to handle significantly larger batches, Lamina emerges as a transformative force in LLM inference, poised to redefine industry standards.
The Road Ahead: A Call to Action
As LLMs ascend towards commoditization, the imperative for cost-efficient inference methodologies intensifies. Attention offloading stands as a beacon of innovation, offering a pathway towards sustainable scalability and economic viability.
Looking Forward
While the code for Lamina remains unreleased, the conceptual framework outlined in the research lays a robust foundation for future endeavors. With the potential to catalyze rapid adoption within the open-source community, attention offloading heralds a new era of efficiency in LLM inference, empowering organizations to unlock the full potential of language models while minimizing capital expenditure.
Conclusion:
The introduction of attention offloading techniques for LLM inference represents a significant milestone in the optimization of computational resources. By strategically reallocating hardware resources and leveraging heterogeneous architectures, organizations can achieve unprecedented efficiency and cost-effectiveness in serving large language models. Lamina’s empirical success underscores the tangible benefits of attention offloading, signaling a transformative shift in the market towards more sustainable and economically viable LLM inference solutions.