
- Google AI introduces innovative methods for creating differentially private synthetic data.
- Aim: Balancing robust model training with user privacy preservation.
- Traditional methods involved direct training with DP-ML algorithms, facing computational challenges.
- Leveraging LLMs and DP-SGD represented progress, but still had limitations.
- Google’s approach incorporates LoRa and prompt fine-tuning for enhanced parameter efficiency.
- LoRa fine-tuning outperforms other methods, balancing computational efficiency and data quality.
- Experimental results show classifiers trained on LoRa fine-tuned synthetic data excel in various tasks.
- Google’s research signifies a significant advancement in privacy-preserving machine learning.
Main AI News:
Google AI researchers have unveiled groundbreaking methods for generating differentially private synthetic data, revolutionizing privacy-preserving machine learning practices. The quest for high-quality synthetic datasets that safeguard user privacy while empowering robust model training has reached a new pinnacle with Google’s innovative approach.
In the ever-expanding landscape of machine learning, the need to ensure the privacy of individuals contributing to large datasets has become paramount. Google’s solution involves the creation of synthetic data that mirrors the essential characteristics of the original dataset but remains entirely artificial, thus shielding user privacy without compromising data utility.
Traditionally, privacy-preserving data generation relied on direct training with differentially private machine learning (DP-ML) algorithms, offering strong privacy assurances. However, grappling with high-dimensional datasets across diverse tasks posed computational challenges and occasionally yielded subpar results. Leveraging large-language models (LLMs) combined with differentially private stochastic gradient descent (DP-SGD) represented a significant leap forward, as seen in previous models like Harnessing large-language models.
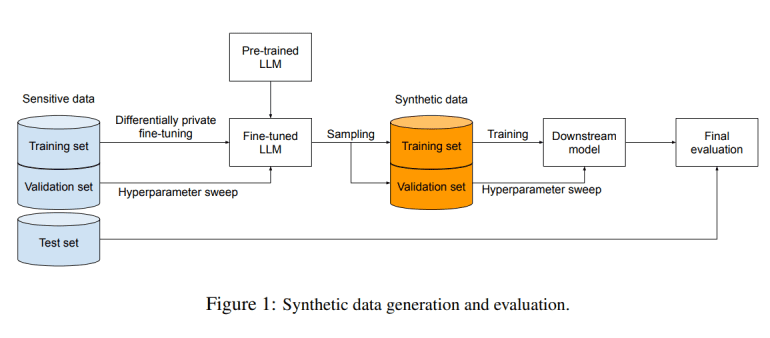
Google’s pioneering approach introduces enhanced techniques such as LoRa (Low-Rank Adaptation) and prompt fine-tuning, aimed at refining a smaller subset of parameters during the private training phase. This strategic focus minimizes computational overhead while potentially enhancing the quality of synthetic data.
The methodology begins with training an LLM on extensive public data, followed by fine-tuning using DP-SGD on the sensitive dataset. LoRa fine-tuning, which replaces select parameters with low-rank matrices, and prompt fine-tuning, which modifies only the input prompt, emerged as standout methods. Empirical evidence showcased LoRa fine-tuning’s superiority, outperforming both full-parameter fine-tuning and prompt-based approaches.
In rigorous experiments evaluating the proposed technique, classifiers trained on synthetic data generated via LoRa fine-tuned LLMs surpassed those from alternative methods and even rivaled classifiers trained directly on original sensitive data using DP-SGD. Notably, in tasks like sentiment analysis and topic classification on datasets such as IMDB, Yelp, and AG News, the efficacy of the approach was underscored by classifiers’ performance on held-out subsets of the original data.
Google’s trailblazing research marks a significant leap forward in the realm of privacy-preserving machine learning, offering a potent arsenal of techniques to generate synthetic data without compromising user privacy or data utility.
Conclusion:
Google’s innovative techniques for generating differentially private synthetic data mark a pivotal advancement in the realm of privacy-preserving machine learning. This development not only strengthens user privacy protection but also enhances the efficacy of model training, offering promising implications for industries reliant on sensitive data while navigating stringent privacy regulations.