
- Meta introduces Chameleon, an early-fusion multimodal Language Learning Model (LLM) in a recent research paper.
- Chameleon integrates visual and textual information seamlessly, enabling advanced AI applications.
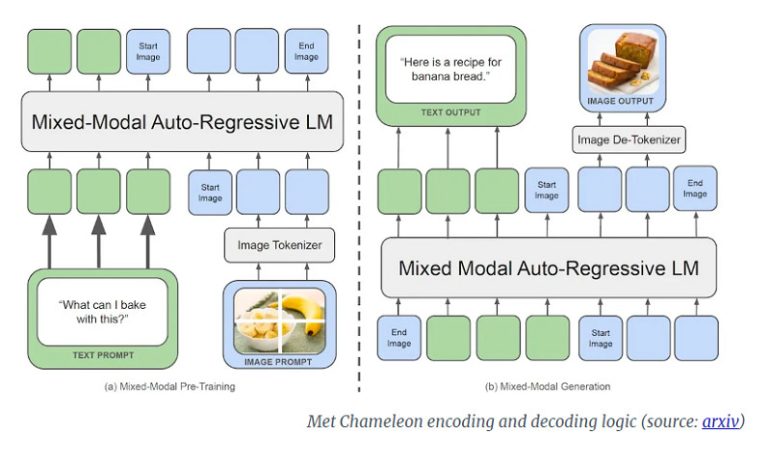
- Unlike ‘late fusion’ models, Chameleon adopts an ‘early fusion’ approach, processing diverse data types simultaneously.
- Chameleon’s architecture involves token-based mixed-modal learning, facilitating the generation of sequences with both image and text tokens.
- It is comparable to Google’s Gemini but distinguishes itself with its end-to-end processing and generation capabilities.
- Despite training challenges, Meta overcomes them with architectural modifications and advanced techniques.
- Chameleon exhibits impressive performance in both text-only and multimodal tasks, setting new benchmarks in visual generation.
- The unveiling of Chameleon amidst fierce competition signals a transformative shift in the AI landscape.
Main AI News:
Meta has unveiled its latest innovation in the realm of artificial intelligence, the Chameleon – a groundbreaking early-fusion multimodal Language Learning Model (LLM). Presented in a recent research paper, Chameleon marks a significant leap forward in AI capabilities by seamlessly integrating visual and textual information, paving the way for a new era of AI applications.
Unlike its predecessors, which relied on ‘late fusion’ techniques, Chameleon adopts an ‘early fusion’ approach right from the onset. This native multimodal architecture enables the model to process and generate diverse types of data simultaneously, without the need for separate training components. In essence, Chameleon emerges as a versatile solution capable of handling tasks previously relegated to disparate models, promising enhanced integration and efficiency in processing both images and text.
Central to Chameleon’s innovative design is its ‘early-fusion token-based mixed-modal’ architecture. By intertwining images, code, text, and other inputs into a unified learning framework, Chameleon transcends conventional boundaries. Leveraging a mixed vocabulary comprising image, text, and code tokens, the model can seamlessly generate sequences encompassing a rich interplay of visual and textual elements.
Drawing parallels with Google’s Gemini, another early-fusion contender, Chameleon sets itself apart with its holistic end-to-end approach. While Gemini employs separate image decoders during the generation phase, Chameleon seamlessly processes and generates tokens within a unified model architecture, promising enhanced coherence and efficiency in multimodal interactions.
Despite the inherent challenges in training and scaling early-fusion LLMs, Meta’s specialists have devised innovative solutions to overcome these hurdles. Through meticulous architectural modifications and advanced training techniques, Meta has succeeded in unleashing the full potential of Chameleon. Training on a vast dataset comprising 4.4 trillion tokens, encompassing text, image-text combinations, and interwoven sequences, Chameleon has undergone rigorous training sessions spanning over 5 million hours on Nvidia A100 80GB GPUs.
The results speak volumes, with Chameleon showcasing remarkable performance across a spectrum of text-only and multimodal tasks. Boasting two variants – one with 7 billion parameters and another with 34 billion parameters – Chameleon emerges as a formidable contender in the AI arena. In visual generation tasks, the 34 billion-parameter variant surpasses benchmarks set by established LLMs such as Flamingo, IDEFICS, and Llava-1.5. In the realm of text-only generation, Chameleon stands toe-to-toe with industry stalwarts like Google’s Gemini Pro and Mistral AI’s Mixtral 8x7B.
As Meta unveils Chameleon amidst a dynamic AI landscape, the stage is set for a relentless pursuit of innovation. With OpenAI’s GPT-4o, Microsoft’s MAI-1, and Google’s Project Astra vying for supremacy, the AI race intensifies, heralding a future defined by unprecedented possibilities. While the release date of Chameleon remains undisclosed, its arrival foreshadows a paradigm shift in AI capabilities, propelling us towards a realm where the boundaries between the virtual and the real blur into insignificance.
Conclusion:
The introduction of Meta’s Chameleon signifies a significant advancement in multimodal AI, challenging established players like Google and OpenAI. With its early fusion capabilities and impressive performance metrics, Chameleon has the potential to reshape the market landscape, offering businesses enhanced capabilities in visual and textual data processing. As competition intensifies, companies must adapt to this paradigm shift, leveraging innovative AI solutions to stay ahead in an increasingly dynamic marketplace.