
- Hunyuan-DiT revolutionizes text-to-image transformation, excelling in both English and Chinese comprehension.
- Its transformer architecture maximizes visual production from textual descriptions, ensuring precise data recording.
- Leveraging bilingual CLIP and multilingual T5 encoders, it adeptly handles linguistic nuances.
- Enhanced positional encoding enables efficient mapping of tokens to image attributes.
- The data pipeline focuses on curation, augmentation, and iterative model optimization.
- A specialized MLLM enhances language understanding precision, improving caption quality.
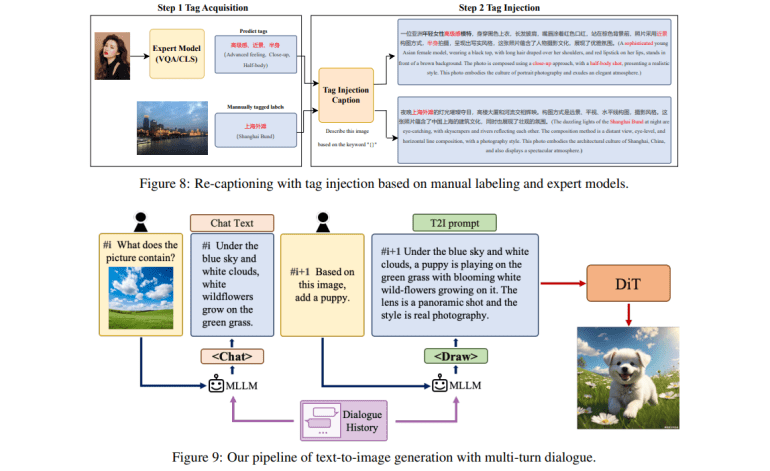
- It facilitates interactive image generation through multi-turn dialogues.
- Rigorous evaluation against open-source models confirms state-of-the-art performance.
Main AI News:
In a recent breakthrough, the cutting-edge text-to-image diffusion transformer known as Hunyuan-DiT emerges, heralding a new era in comprehensive comprehension of both English and Chinese textual prompts. Meticulously crafted, Hunyuan-DiT embodies a sophisticated fusion of essential components and meticulous procedures, all aimed at ensuring unparalleled image generation and nuanced linguistic comprehension.
Exploring the Core Components:
- Transformer Architecture: At the heart of Hunyuan-DiT lies its meticulously engineered transformer structure, meticulously tailored to unleash the model’s prowess in translating textual descriptions into vivid visuals. This entails enhancing the model’s capacity to decipher complex linguistic inputs while meticulously recording precise data, thus laying the foundation for impeccable image synthesis.
- Bilingual and Multilingual Encoding: Central to Hunyuan-DiT’s proficiency in interpreting prompts is its adept utilization of cutting-edge text encoders. Harnessing the combined strengths of a bilingual CLIP encoder adept at handling both English and Chinese, alongside a multilingual T5 encoder, the model excels in grasping context nuances with unparalleled finesse.
- Enhanced Positional Encoding: The positional encoding algorithms of Hunyuan-DiT have been meticulously fine-tuned to adeptly navigate the sequential nature of text and the spatial intricacies of images. This optimization significantly bolsters the model’s capability to accurately map tokens to their corresponding image attributes while preserving the inherent token sequence.
Empowering Data Pipeline
In a bid to fortify and augment Hunyuan-DiT’s capabilities, the development team has meticulously devised an extensive data pipeline comprising the following components:
- Data Curation and Collection: Rigorous aggregation of a diverse and extensive corpus of text-image pairings forms the cornerstone of Hunyuan-DiT’s data pipeline.
- Data Augmentation and Filtering: Leveraging advanced data augmentation techniques, supplemented by meticulous filtering processes, the team ensures the enrichment of the dataset while mitigating the inclusion of superfluous or low-quality data instances.
- Iterative Model Optimization: Embracing a philosophy of continuous improvement, the team relentlessly refines and enhances the model’s performance through iterative optimization fueled by fresh data insights and user feedback, epitomizing the ‘data convoy’ paradigm.
Elevating Language Understanding Precision
To further augment the model’s language comprehension precision, the team has pioneered the training of a specialized MLLM (Multimodal Language and Vision Model). By harnessing contextual cues, this advanced model meticulously crafts captions that exhibit unparalleled accuracy and granularity, thereby elevating the quality of the resultant images.
Pioneering Interactive Image Generation
Hunyuan-DiT heralds a paradigm shift with its facilitation of multi-turn dialogues, fostering interactive image generation. This groundbreaking capability empowers users to iteratively refine and enhance generated images through successive rounds of engagement, culminating in outcomes characterized by heightened accuracy and aesthetic appeal.
Rigorous Evaluation Framework
In a testament to its unparalleled performance, Hunyuan-DiT undergoes rigorous evaluation under the scrutiny of a meticulously crafted methodology, involving over 50 qualified evaluators. This comprehensive framework meticulously assesses key parameters including subject clarity, visual fidelity, absence of AI artifacts, text-image coherence, among others. Comparative analyses against existing open-source models unequivocally demonstrate Hunyuan-DiT’s prowess in Chinese-to-image synthesis, delivering state-of-the-art performance characterized by crisp, semantically coherent visuals in response to Chinese cues.
Conclusion:
The emergence of Hunyuan-DiT signifies a pivotal advancement in the text-to-image transformation landscape, offering unparalleled precision in language understanding and multi-turn interactive capabilities. Its proficiency in comprehending both English and Chinese prompts, coupled with state-of-the-art image synthesis, positions it as a game-changer in various industries requiring advanced AI-driven visual content generation. Market players should take note of its capabilities and consider integrating Hunyuan-DiT into their workflows to stay ahead in an increasingly competitive landscape.