
- Apple researchers introduce KV-Runahead, a specialized parallelization technique for LLM inference, aiming to reduce time-to-first-token (TTFT).
- KV-Runahead optimizes KV-cache population across processes, enhancing context-level load-balancing and leveraging causal attention computation.
- Contrasted with traditional methods like Tensor/Sequence Parallel Inference (TSP), KV-Runahead demonstrates superior performance, especially with longer contexts and multiple GPUs.
- Experimental evaluations on NVidia A100 GPUs underline KV-Runahead’s efficiency, even on low bandwidth networks, showcasing robustness against non-uniform network bandwidth.
Main AI News:
In the realm of large language models (LLMs), particularly the renowned Generative Pre-trained Transformer (GPT) models, remarkable strides have been made in various language tasks. Nonetheless, persistent challenges reside within their decoder architecture, notably in reducing the time-to-first-token (TTFT) and time-per-output token (TPOT). These challenges, reliant on extensive user context and rapid subsequent token generation, have prompted extensive research into memory-bound solutions such as sparsification and speculative decoding. While parallelization methods, including tensor and sequential approaches, have addressed compute-bound TTFT, there remains a notable gap in optimizing scalable LLM inference due to inefficiencies in attention computation and communication.
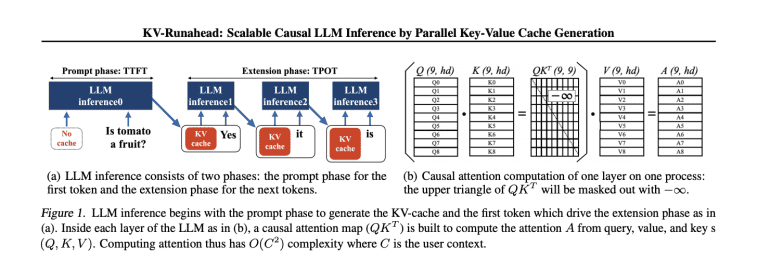
Generative LLM inference comprises two pivotal phases: a prompt phase, where initial tokens are generated based on user context, and an extension phase utilizing cached key-value embeddings to expedite subsequent token generation. To mitigate TTFT for lengthy contexts, efficient KV-cache management and swift attention map computation are imperative. Various optimization strategies, such as PagedAttention and CacheGen, have been devised to tackle these challenges. Despite these efforts, parallelization techniques like tensor and sequence parallelism aim to optimize compute-bound TTFT, with innovations like KV-Runahead emerging to further enhance scalability and load balancing for improved inference efficiency.
Presented by Apple researchers, KV-Runahead is a pioneering parallelization technique tailored specifically for LLM inference to minimize TTFT. Leveraging the existing KV cache mechanism, KV-Runahead optimizes by redistributing the KV-cache population across processes, ensuring context-level load-balancing. By harnessing causal attention computation inherent in KV-cache, KV-Runahead effectively diminishes computation and communication costs, resulting in reduced TTFT compared to existing methodologies. Notably, its implementation requires minimal engineering effort, as it repurposes the KV-cache interface without significant modifications.
Contrasting with traditional Tensor/Sequence Parallel Inference (TSP), which evenly distributes computation across processes, KV-Runahead stands out by utilizing multiple processes to populate KV-caches for the final process. This necessitates effective context partitioning for load-balancing. Subsequently, each process executes layers, awaiting KV-cache from the preceding process via local communication rather than global synchronization.
Experimental evaluations conducted on a single node equipped with 8× NVidia A100 GPUs, under both high (300GB/s) and low (10GB/s) bandwidth conditions, showcased the superiority of KV-Runahead. Utilizing FP16 for inference, KV-Runahead consistently outperformed TSP across various scenarios. Different variants of KV-Runahead, including KVR-E with even context partitioning, KVR-S with searched partitioning, and KVR-P with predicted partitioning, were evaluated for efficiency. Remarkably, KV-Runahead exhibited significant speedups, particularly with longer contexts and more GPUs, surpassing TSP even on low bandwidth networks. Moreover, KV-Runahead demonstrated robustness against non-uniform network bandwidth, underscoring the advantages of its communication mechanism.
Conclusion:
Apple’s development of KV-Runahead signifies a significant leap forward in enhancing the efficiency of large language model inference processes. By reducing time-to-first-token and optimizing context-level load-balancing, KV-Runahead presents a promising solution for industries reliant on rapid and scalable language model deployment, potentially revolutionizing the landscape of natural language processing technologies in the market.