
- Speech recognition technology evolves for higher transcription accuracy.
- Denoising LM (DLM) emerges to rectify errors in ASR systems.
- DLM leverages synthetic data from TTS systems, surpassing prior models.
- DLM synthesizes audio, corrects errors, and achieves state-of-the-art performance.
- Versatility and adaptability make DLM a promising replacement for traditional LMs.
Main AI News:
In the realm of speech recognition technology, the quest for accurate transcription from spoken language remains paramount. This endeavor encompasses intricate processes such as acoustic modeling, language modeling, and decoding, all aimed at achieving precision in transcriptions. The journey toward this goal has witnessed significant strides, propelled by the prowess of machine learning algorithms and the abundance of expansive datasets. These advancements herald a new era of more precise and efficient speech recognition systems, pivotal for an array of applications spanning virtual assistants, transcription services, and accessibility tools.
Yet, amidst these advancements, a persistent challenge looms large: the rectification of errors stemming from automatic speech recognition (ASR) systems. Traditional language models (LMs) integrated with ASR systems often grapple with the need to discern specific errors, thereby compromising performance. The quest for error correction models capable of rectifying these errors with precision, and without an exhaustive reliance on supervised training data, stands as a pivotal frontier. This challenge assumes even greater significance in light of the escalating dependence on ASR systems across everyday technology and communication platforms.
Enterprising endeavors to address this challenge have yielded promising techniques, ranging from integrating LMs with neural acoustic models employing sequence discriminative criteria to merging text-only LM features with ASR models. Central to these efforts are error correction models that refine ASR outputs, elevating transcription accuracy by transforming noisy hypotheses into pristine text. Notably, transformer-based error correction models have witnessed significant strides, particularly through the deployment of advanced metrics rooted in word error rate (WER) and innovative noise augmentation strategies. Moreover, recent advancements have delved into the realm of large language models (LLMs), exemplified by the likes of ChatGPT, to bolster transcription accuracy through robust linguistic representations.
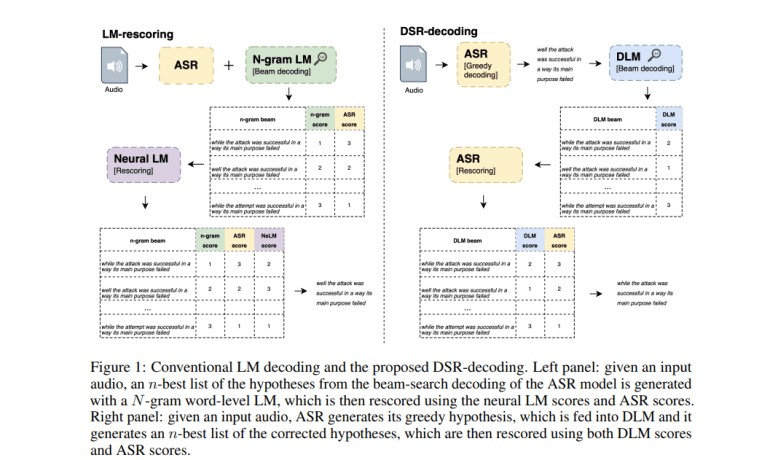
A groundbreaking contribution in this domain comes from the research enclave of Apple, with the unveiling of the Denoising LM (DLM). Representing a paradigm shift in error correction models, the DLM emerges as a beacon of innovation, crafted by a cadre of researchers at Apple. Leveraging copious amounts of synthetic data generated by Text-to-Speech (TTS) systems, the DLM charts a course towards unparalleled efficacy. This novel approach surmounts prior limitations, catapulting the DLM to the zenith of ASR performance.
The modus operandi of the DLM hinges upon the synthesis of audio utilizing TTS systems, subsequently funneled into an ASR framework to yield noisy hypotheses. These hypotheses, in tandem with the original texts, form the bedrock of the DLM’s training dataset. At its core, the DLM encompasses pivotal components such as up-scaled models and data, multi-speaker TTS systems, an array of noise augmentation strategies, and pioneering decoding techniques. Specifically, the model draws upon textual inputs from a vast language model corpus to engender audio, which is then subjected to ASR processing, thereby yielding noisy transcriptions. This symbiotic interplay between synthesized audio and original text underpins the DLM’s efficacy, enabling it to traverse a diverse spectrum of ASR errors with finesse, rendering it remarkably versatile and scalable.
The empirical prowess of the DLM stands testament to its efficacy, as evidenced by its remarkable performance boasting a mere 1.5% word error rate (WER) on the Librispeech test-clean dataset and 3.3% on the test-other dataset. These results resonate profoundly, matching or surpassing the performance benchmarks set by conventional LMs and even eclipsing certain self-supervised methodologies leveraging external audio data. The DLM’s penchant for enhancing ASR accuracy underscores its potential to supplant traditional LMs within ASR frameworks. Furthermore, its adaptability across diverse ASR architectures underscores a pivotal advantage, auguring well for seamless integration into an extensive array of ASR applications.
Conclusion:
The introduction of Denoising LM (DLM) signifies a pivotal leap in enhancing speech recognition accuracy, addressing longstanding challenges in error correction. Its ability to surpass conventional models and adapt to diverse ASR architectures heralds a transformative shift in the market, with implications for industries reliant on precise transcription services. As DLM continues to evolve, it holds the promise of revolutionizing the landscape of speech recognition technology and shaping future innovations in communication and accessibility solutions.