
- Vision-Language Models combine computer vision and natural language processing.
- Challenges include aligning visual and textual data.
- Methods like contrastive training and masking improve model understanding.
- Collaborative efforts yield efficient models with pre-trained backbones.
- Methodologies integrate transformer architectures, image encoders, and text decoders.
- CLIP and CoCa exemplify effective alignment and generation approaches.
- Performance metrics highlight zero-shot classification accuracy and state-of-the-art results.
- FLAVA and LLaVA-RLHF models excel in image captioning and factual accuracy tasks.
Main AI News:
Vision-Language Models represent a significant leap forward in artificial intelligence, seamlessly blending computer vision with natural language processing capabilities. These cutting-edge models underpin a spectrum of applications, ranging from image captioning to visual question answering and even generating images from textual inputs, thus revolutionizing human-computer interaction capabilities.
Central to the advancement of vision-language modeling is the challenge of harmonizing high-dimensional visual data with discrete textual information. This incongruity often presents obstacles in accurately interpreting and generating cohesive text-vision interactions, necessitating innovative methodologies to bridge this gap effectively.
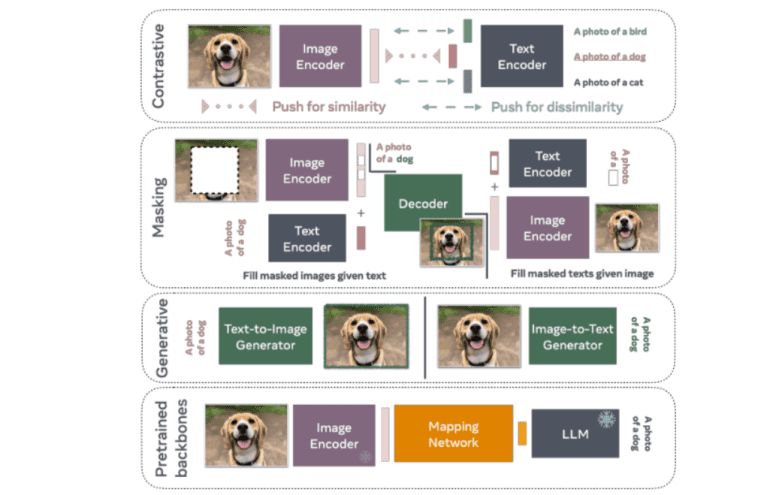
In the realm of vision-language modeling, several approaches have emerged, each addressing this challenge uniquely. Techniques such as contrastive training, masking strategies, and generative models stand out among the array of methodologies employed. Contrastive methods, exemplified by CLIP, train models to predict similar representations for related image-text pairs, fostering a cohesive understanding of multimodal data. Meanwhile, masking involves reconstructing obscured portions of images or text, while generative models focus on creating new visual or textual content based on input prompts.
A collaborative effort among researchers from Meta, MIT, NYU, and other esteemed institutions has yielded various Vision-Language Models, harnessing pre-trained backbones to streamline computational overheads. Leveraging techniques like contrastive loss, masking, and generative components, these models exhibit enhanced capabilities in understanding and generating multimodal content. Typically built upon transformer architectures, these models integrate image encoders and text decoders seamlessly. For instance, CLIP employs contrastive loss to align image and text embeddings within a shared space, facilitating robust multimodal comprehension. Similarly, generative models like CoCa employ multimodal text decoders to excel in tasks such as image captioning, bolstering the model’s prowess in generating contextually relevant textual descriptions.
Furthermore, methodologies like VILA and LAION-aesthetics delve into assessing the aesthetic quality of images, thereby refining image generation models by selecting high-quality subsets of data.
Analyzing the Strategies: A Deep Dive into Methodologies
The methodologies employed in Vision-Language Models entail a sophisticated fusion of transformer architectures, image encoders, and text decoders. A standout approach, CLIP, pioneered by researchers at OpenAI, harnesses contrastive loss to align image and text embeddings within a unified space. This methodology empowers the model to glean representations that encapsulate both visual and textual cues adeptly. Through the meticulous pairing of images with corresponding textual descriptions during training, the model evolves a nuanced comprehension of the intricate relationships between visual and textual data.
Conversely, generative models like CoCa, introduced by Google researchers, adopt a distinct paradigm by integrating multimodal text decoders. This innovative setup enables the model to excel in tasks such as image captioning with exceptional precision. By training the multimodal text decoder to craft descriptive captions for given images, the model’s proficiency in generating coherent and contextually relevant textual output from visual stimuli is greatly amplified.
Another pivotal methodology involves the strategic utilization of masking strategies. This entails selectively masking portions of input data—be it images or text—and training the model to predict the concealed content. Such an approach fortifies the model’s resilience and its capacity to handle incomplete or partially visible data, thereby enhancing its efficacy in real-world scenarios characterized by noisy or incomplete data.
Performance Metrics and Groundbreaking Achievements
The performance of Vision-Language Models is rigorously evaluated across diverse benchmarks, yielding profound insights into their efficacy and versatility. Notably, the CLIP model has garnered acclaim for achieving remarkable zero-shot classification accuracy, signifying its adeptness in categorizing images without explicit training on specific categories within the test set. This exceptional performance underscores the model’s capacity to extrapolate insights from its training data to novel, unseen categories.
Equally noteworthy is the groundbreaking performance of the FLAVA model, which has established new benchmarks across various tasks encompassing vision, language, and multimodal integration. Notably, FLAVA has demonstrated exceptional prowess in image captioning tasks, generating high-fidelity captions that accurately encapsulate the essence of the corresponding images. Additionally, the model’s performance in visual question answering tasks has been exemplary, showcasing substantial advancements over preceding models.
Moreover, the LLaVA-RLHF model, a collaborative endeavor between MIT and NYU, has attained an impressive performance level, boasting a 94% efficacy compared to GPT-4. Furthermore, on the MMHAL-BENCH benchmark, which prioritizes minimizing hallucinations and enhancing factual accuracy, LLaVA-RLHF has outshone baseline models by a staggering 60%. These results underscore the efficacy of reinforcement learning from human feedback (RLHF) in refining model outputs to align more closely with human expectations and factual accuracy benchmarks.
Conclusion:
The advancements in Vision-Language Models underscore a transformative shift in artificial intelligence capabilities. With improved understanding and generation of multimodal data, these models hold immense potential across various industries. From enhancing human-computer interaction to refining image generation and factual accuracy, businesses can leverage these innovations to streamline processes, improve decision-making, and drive meaningful outcomes in the market.