
- Google DeepMind introduces Zipper, a multi-tower decoder framework for fusing modalities in AI.
- Zipper integrates multiple generative foundation models, enhancing cross-modal task performance.
- Challenges addressed include aligned data availability and effective utilization of unimodal representations.
- Zipper utilizes independently pre-trained unimodal decoders and innovative cross-attention mechanisms.
- The architecture comprises autoregressive decoder towers combined via gated cross-attention layers.
- Experimental results showcase Zipper’s competitive performance and superior flexibility.
- Zipper achieves meaningful results with minimal training data, underscoring its real-world applicability.
Main AI News:
In the contemporary landscape of AI, the amalgamation of various generative foundation models stands as a cornerstone for unlocking the true potential of cross-modal tasks. The synergy of models trained on distinct modalities—be it text, speech, or images—heralds a new era of efficiency and efficacy in AI systems. It is within this realm that Google DeepMind has introduced Zipper, a groundbreaking solution designed to seamlessly integrate multiple generative foundation models into a unified architecture, transcending the limitations of mere concatenation.
The integration of diverse generative models poses two primary challenges: the availability of aligned data across modalities and the effective utilization of unimodal representations in cross-domain generative tasks without compromising their inherent capabilities. Traditional approaches often grapple with inflexibility in accommodating new modalities post-pre-training and the exigency for copious amounts of aligned cross-modal data, particularly when dealing with emerging modalities.
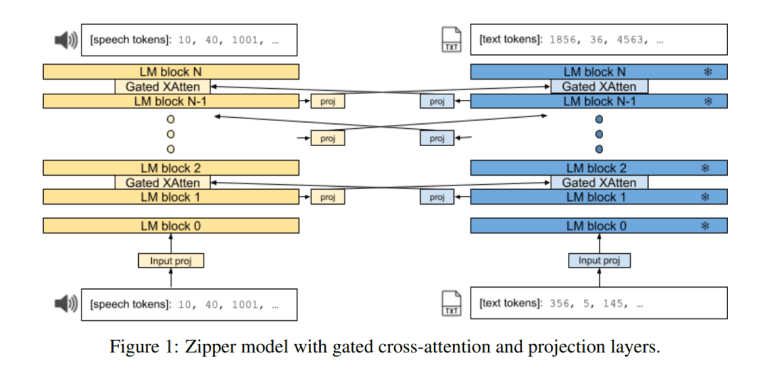
Enter Zipper, a paradigm-shifting architecture devised by Google DeepMind researchers to tackle these challenges head-on. Unlike conventional methods, Zipper eschews the constraints of vocabulary expansion techniques and fine-tuning on aligned data. Instead, it leverages independently pre-trained unimodal decoders, seamlessly weaving them together through innovative cross-attention mechanisms. This ingenious approach not only ensures flexibility in modality integration but also preserves the innate performance of unimodal models.
At its core, the Zipper architecture comprises multiple autoregressive decoder towers, each meticulously pre-trained on a singular modality using next-token prediction. These decoders are ingeniously fused using gated cross-attention layers, facilitating the seamless exchange of information between modalities. Moreover, the architecture employs projection layers to equalize embedding dimension size disparities and seamlessly transform representations across modalities during cross-attention.
In practical applications, Zipper shines through its exceptional performance, even with minimal training data. Experimental evaluations employing variants of PaLM2 models for the text backbone and analogous architectures for the speech backbone underscore Zipper’s prowess. Notably, Zipper exhibits competitive performance with the baseline, demonstrating negligible impact on automatic speech recognition (ASR) when freezing the text backbone. Furthermore, Zipper outperforms the baseline in Text-to-Speech tasks, particularly when the speech backbone remains unfrozen. These findings underscore Zipper’s remarkable ability to preserve unimodal capabilities while enhancing alignment capabilities through cross-attention mechanisms.
Conclusion:
The introduction of Zipper by Google DeepMind signifies a significant advancement in multimodal generative modeling. This innovative architecture not only enhances cross-modal task performance but also addresses key challenges such as data alignment and modality integration flexibility. With its ability to achieve meaningful results with minimal training data, Zipper holds immense promise for revolutionizing AI applications across diverse industries, paving the way for more efficient and versatile AI systems.