
- Hugging Face introduces FineWeb, a groundbreaking dataset for large language model (LLM) training.
- FineWeb is sourced from 96 CommonCrawl snapshots, containing an impressive 15 trillion tokens spread across 44TB of disk space.
- The dataset implements meticulous deduplication techniques using MinHash, ensuring optimal model performance by eliminating redundant data.
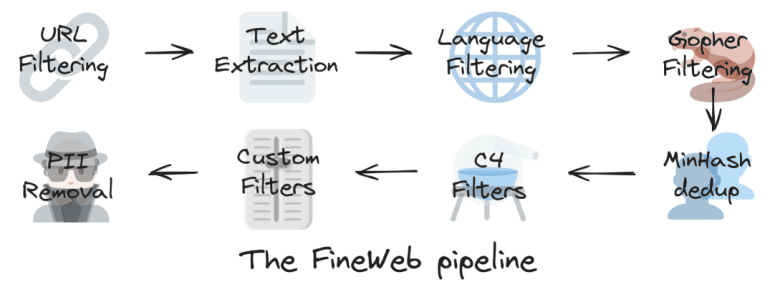
- FineWeb prioritizes quality through advanced filtering strategies, including language classification, URL filtration, and heuristic filters.
- FineWeb-Edu, a specialized subset, focuses on educational content and is curated using synthetic annotations, resulting in a corpus optimized for educational benchmarks.
- Rigorous benchmarking confirms FineWeb’s superiority over other open web-scale datasets, with FineWeb-Edu showcasing remarkable improvements.
Main AI News:
Hugging Face has recently unveiled FineWeb, a robust dataset meticulously crafted to bolster the training of large language models (LLMs). Released on May 31, 2024, this dataset marks a significant advancement in LLM pretraining, boasting superior performance facilitated by its meticulous data curation and innovative filtering methodologies.
FineWeb taps into the vast repository of 96 CommonCrawl snapshots, comprising an astonishing 15 trillion tokens and spanning a colossal 44TB of disk space. Leveraging the resources provided by CommonCrawl, a non-profit entity dedicated to web archiving since 2007, Hugging Face has meticulously compiled a diverse and extensive dataset aimed at surpassing the capabilities of previous benchmarks like RefinedWeb and C4.
A key highlight of FineWeb lies in its stringent deduplication process. Employing MinHash, a sophisticated fuzzy hashing technique, the Hugging Face team has effectively eradicated redundant data, thereby enhancing model performance by mitigating the memorization of duplicate content and optimizing training efficiency. The dataset underwent both individual and global deduplication processes, with the former proving particularly advantageous in preserving high-quality data.
Central to FineWeb’s ethos is its unwavering commitment to quality. The dataset incorporates advanced filtering mechanisms to eliminate low-quality content. Initial measures encompassed language classification and URL filtration to exclude non-English text and adult material. Building upon the groundwork laid by C4, additional heuristic filters were implemented, including the removal of documents featuring excessive boilerplate content or failing to punctuate sentence endings.
Complementing the primary dataset is FineWeb-Edu, a specialized subset tailored for educational purposes. This subset was meticulously curated using synthetic annotations generated by Llama-3-70B-Instruct, which evaluated 500,000 samples based on their academic merit. Subsequently, a classifier trained on these annotations was deployed to filter out non-educational content from the entire dataset, resulting in a corpus of 1.3 trillion tokens optimized for educational benchmarks such as MMLU, ARC, and OpenBookQA.
FineWeb has undergone rigorous benchmarking against various standards, consistently surpassing competing open web-scale datasets. The dataset’s performance has been validated through a series of “early-signal” benchmarks employing small models. These benchmarks include CommonSense QA, HellaSwag, and OpenBook QA, among others. Notably, FineWeb-Edu showcased significant enhancements, underscoring the efficacy of synthetic annotations in filtering high-quality educational content.
Conclusion:
The introduction of FineWeb signifies a paradigm shift in LLM training, offering researchers and developers a comprehensive and high-quality dataset unparalleled in scale and performance. Its advanced deduplication and filtering techniques ensure the integrity of the data, while specialized subsets like FineWeb-Edu cater to specific needs, such as educational content. This innovation not only enhances the capabilities of existing language models but also opens doors for new applications and advancements in natural language processing. Companies investing in language technologies will find FineWeb to be a valuable asset in driving innovation and staying competitive in a rapidly evolving market landscape.