
- Jina AI introduces Jina CLIP, a state-of-the-art multimodal (text-image) embedding model.
- Current models struggle with text-only and text-image tasks, necessitating separate systems.
- Jina-clip-v1 addresses this by optimizing text-image and text-text alignment in a unified model.
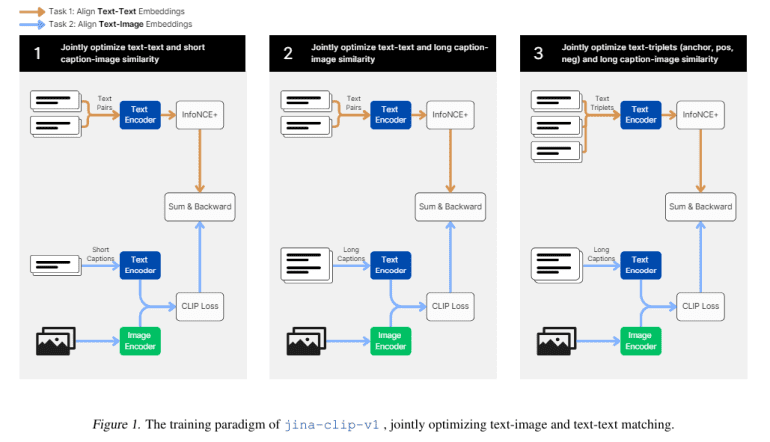
- The model undergoes a three-stage training process focusing on alignment, performance enhancement, and fine-tuning.
- Jina-clip-v1 outperforms existing models in text-image and retrieval tasks, achieving superior results.
- Evaluation involves leveraging extensive datasets and synthetic data to improve performance across various benchmarks.
Main AI News:
In the rapidly evolving landscape of multimodal learning, there’s a crucial focus on equipping models to comprehend and produce content spanning various modalities like text and images. Through harnessing extensive datasets, these models can align visual and textual representations within a shared embedding space, paving the way for applications such as image captioning and text-to-image retrieval. This integrated methodology aims to amplify the model’s adeptness in handling a spectrum of data inputs more effectively.
The primary issue tackled in this study is the inefficiency plaguing current models in handling text-only and text-image tasks. Typically, existing models excel in one domain while faltering in the other, necessitating the deployment of distinct systems for different types of information retrieval. This dichotomy escalates the complexity and resource requirements of such systems, underscoring the imperative for a more cohesive approach.
Approaches like Contrastive Language-Image Pre-training (CLIP) align images and text via pairs of images and their corresponding captions. However, these models often grapple with text-only tasks as they struggle to process longer textual inputs. This limitation translates to subpar performance in scenarios requiring efficient comprehension of larger textual datasets, thereby impeding the handling of tasks reliant on robust understanding of extensive textual content.
To address these challenges, Jina AI Researchers introduced the groundbreaking Jina-clip-v1 model, now open-sourced. This model employs an innovative multi-task contrastive training paradigm meticulously crafted to optimize the alignment of text-image and text-text representations within a singular framework. The overarching objective is to synergize the proficiency in handling both task types effectively, thereby mitigating the necessity for disparate models.
The proposed training methodology for jina-clip-v1 entails a meticulous three-stage process. The initial stage centers on aligning image and text representations utilizing concise, human-curated captions, laying the groundwork for multimodal tasks. Subsequently, in the second stage, researchers introduced lengthier, synthetic image captions to bolster the model’s prowess in text-text retrieval endeavors. The culmination of the process involves leveraging hard negatives to fine-tune the text encoder, augmenting its discernment of relevant versus irrelevant texts while upholding text-image alignment.
Performance assessments underscore jina-clip-v1’s supremacy in text-image and retrieval tasks. Notably, the model attained an average Recall@5 of 85.8% across all retrieval benchmarks, outshining OpenAI’s CLIP model and performing comparably to EVA-CLIP. Furthermore, in the extensive Massive Text Embedding Benchmark (MTEB), encompassing eight tasks across 58 datasets, Jina-clip-v1 rivals top-tier text-only embedding models, securing an average score of 60.12%. This represents a significant enhancement over other CLIP variants, with an approximate overall improvement of 15% and a 22% boost in retrieval tasks.
The exhaustive evaluation spanned multiple training stages. For text-image training in Stage 1, the model leveraged the LAION-400M dataset, housing a staggering 400 million image-text pairs. While this stage witnessed notable strides in multimodal performance, initial setbacks in text-text performance arose due to disparities in text lengths across training data categories. Subsequent stages entailed the incorporation of synthetic data featuring extended captions and the utilization of hard negatives, culminating in enhanced text-text and text-image retrieval capabilities.
Conclusion:
The introduction of Jina CLIP represents a significant advancement in multimodal learning, particularly in aligning text and image representations within a single model. By addressing the inefficiencies of current models and achieving superior performance in text-image and retrieval tasks, Jina AI’s innovation is poised to disrupt the market, offering more efficient solutions for handling diverse data inputs and enhancing the capabilities of applications such as image captioning and text-to-image retrieval. Businesses and industries reliant on multimodal learning can anticipate improved efficiency and effectiveness in their operations with the adoption of this groundbreaking technology.