
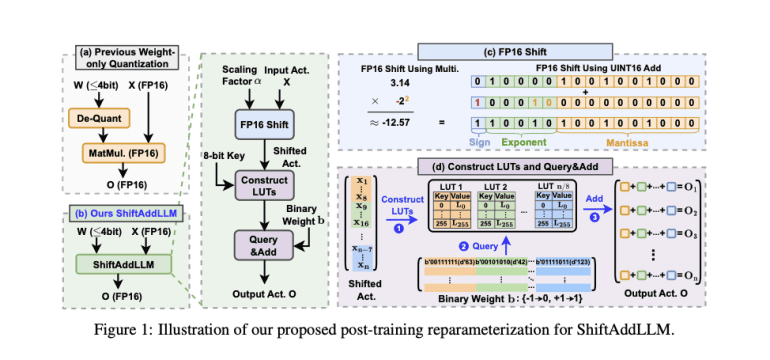
- ShiftAddLLM enhances efficiency of large language models (LLMs) through post-training shift-and-add reparameterization.
- It replaces dense multiplications with hardware-friendly shift and add operations, reducing memory usage and latency.
- The method maintains or improves model accuracy by minimizing reparameterization errors through multi-objective optimization.
- Experimental results show ShiftAddLLM achieves significant reductions in perplexity scores and improvements in latency compared to existing quantized LLMs.
- It validates its effectiveness across various LLM families and tasks, demonstrating potential for widespread application in resource-constrained environments.
Main AI News:
The deployment of large language models (LLMs) on resource-constrained devices poses significant challenges due to their extensive parameters and reliance on dense multiplication operations. This results in high memory demands and latency bottlenecks, limiting their practical application in real-world scenarios. For instance, models such as GPT-3 require substantial computational resources, rendering them unsuitable for edge and cloud environments. Overcoming these challenges is pivotal for advancing AI, facilitating the efficient deployment of powerful LLMs and broadening their applicability and impact.
To address these issues, current methods focus on enhancing LLM efficiency through techniques such as pruning, quantization, and attention optimization. While pruning reduces model size by eliminating less significant parameters, it often comes at the cost of accuracy. Post-training quantization (PTQ) reduces memory and computation demands by reducing the bit-width of weights and activations, yet it can lead to accuracy loss or require extensive retraining.
In response, researchers from Google, Intel, and Georgia Institute of Technology have introduced ShiftAddLLM. This innovative approach accelerates pre-trained LLMs through post-training shift-and-add reparameterization, replacing traditional multiplications with hardware-friendly shift and add operations. The method involves quantizing weight matrices into binary form with group-wise scaling factors, reparameterizing multiplications into shifts and additions between activations and scaling factors based on these binary matrices. This approach minimizes reparameterization errors and significantly reduces memory usage and latency while maintaining or even improving model accuracy.
ShiftAddLLM leverages a multi-objective optimization framework to align weight and output activation objectives, effectively minimizing overall reparameterization errors. The introduction of an automated bit allocation strategy optimizes the bit-widths for weights in each layer based on their sensitivity to reparameterization, ensuring higher-bit representations for more sensitive layers to prevent accuracy loss.
Experimental validation across five LLM families and eight tasks demonstrates ShiftAddLLM’s effectiveness. The method achieves average perplexity improvements of 5.6 and 22.7 points compared to existing quantized LLMs at comparable or lower latency levels. Moreover, ShiftAddLLM achieves over 80% reductions in memory and energy consumption, highlighting its efficiency in resource utilization.
Conclusion:
The introduction of ShiftAddLLM marks a significant advancement in the efficiency of large language models. By addressing challenges related to memory usage, latency, and energy consumption, ShiftAddLLM enhances the feasibility of deploying powerful AI models in resource-constrained environments. This innovation not only broadens the applicability of LLMs but also underscores the ongoing evolution towards more efficient and impactful AI technologies in the market.