
- Apple introduces the 4M-21, a sophisticated multimodal AI model.
- It handles over 20 modalities including SAM segments, 3D human poses, and color palettes.
- The model uses modality-specific tokenizers to unify diverse inputs effectively.
- Capabilities include multimodal generation, retrieval, and strong task performance.
- Scaling studies show promising results with larger model sizes enhancing performance.
Main AI News:
In the realm of large language models (LLMs), advancements have been significant in handling multiple modalities and tasks. However, there remains a critical need for enhancing their ability to process varied inputs effectively across a wide spectrum of tasks. The challenge lies in developing a singular neural network capable of maintaining high performance across diverse domains. While models like 4M and UnifiedIO show promise, they are limited by the range of tasks and modalities they can effectively handle. This limitation poses barriers to their practical application in scenarios demanding versatile and adaptable AI systems.
Recent innovations in multitask learning have evolved from integrating dense vision tasks to encompassing multiple tasks within unified multimodal models. Techniques such as Gato, OFA, Pix2Seq, UnifiedIO, and 4M transform various modalities into discrete tokens and train Transformers using sequence or masked modeling objectives. Some approaches enable a broad spectrum of tasks through co-training on disjoint datasets, while others, like 4M, utilize pseudo labeling for predicting any-to-any modality on aligned datasets. Masked modeling has proven effective in learning cross-modal representations essential for multimodal learning, enabling generative applications in conjunction with tokenization.
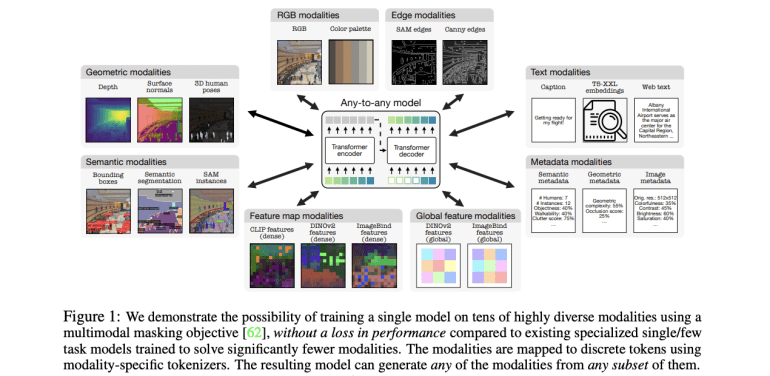
Researchers from Apple and EPFL build upon the multimodal masking pre-training scheme to significantly enhance capabilities by training across more than 20 modalities. This approach includes SAM segments, 3D human poses, Canny edges, color palettes, and various metadata and embeddings. By employing modality-specific discrete tokenizers, diverse inputs are encoded into a unified format, allowing a single model to train on multiple modalities without performance degradation. This unified approach expands capabilities across several axes, including increased modality support, improved diversity in data types, effective tokenization techniques, and scaled model size. The resulting model opens new avenues for multimodal interaction, such as cross-modal retrieval and highly adaptable generation across all training modalities.
Building on the 4M pre-training scheme, this method extends its capacity to handle a diverse set of modalities by transforming them into sequences of discrete tokens using modality-specific tokenizers. The training objective involves predicting subsets of tokens from each other, using random selections from all modalities as inputs and targets. Pseudo-labeling is employed to generate a large pre-training dataset with aligned modalities. The method integrates various modalities, including RGB, geometric, semantic, edges, feature maps, metadata, and text. Tokenization plays a crucial role in unifying the representation space across these diverse modalities, enabling training with a single objective, enhancing training stability, allowing full parameter sharing, and eliminating the need for task-specific components. Three main types of tokenizers are utilized: ViT-based for image-like modalities, MLP for human poses and global embeddings, and WordPiece for text and structured data. This comprehensive tokenization approach enables efficient handling of a broad array of modalities, reducing computational complexity and facilitating generative tasks across multiple domains.
The 4M-21 model showcases extensive capabilities, including versatile multimodal generation, multimodal retrieval, and robust performance across various vision tasks. It can predict any training modality through iterative token decoding, facilitating nuanced multimodal generation with enhanced text comprehension. The model conducts multimodal retrievals by predicting global embeddings from any input modality, enabling versatile retrieval capabilities. In out-of-the-box assessments, 4M-21 achieves competitive performance in tasks like surface normal estimation, depth estimation, semantic and instance segmentation, 3D human pose estimation, and image retrieval. Often, it matches or surpasses specialized models and pseudo-labelers while remaining a singular model for all tasks. Particularly, the 4M-21 XL variant demonstrates strong performance across multiple modalities without compromising capability in any domain.
Researchers investigate the scalability of pre-training models on a wide range of modalities, comparing sizes B, L, and XL. Evaluations encompass both unimodal (RGB) and multimodal (RGB + Depth) transfer learning scenarios. In unimodal transfers, 4M-21 sustains performance on tasks akin to the original seven modalities while exhibiting improved results in complex tasks such as 3D object detection. With increasing size, the model shows enhanced performance, suggesting promising scalability trends. For multimodal transfers, 4M-21 effectively utilizes optional depth inputs, surpassing baseline performances significantly. The study underscores that training across a broader set of modalities does not compromise performance on familiar tasks and can enhance capabilities in new domains, particularly with larger model sizes.
Conclusion:
This advancement with Apple’s 4M-21 signifies a significant leap in multimodal AI capabilities, addressing the growing demand for versatile and efficient AI solutions across diverse tasks and modalities. By expanding its model to encompass a wide range of inputs and enhancing performance metrics across various domains, Apple is poised to set new standards in the AI market. This development underscores the potential for broader application in fields requiring robust multimodal capabilities, from healthcare diagnostics to autonomous systems and beyond.