
- Salesforce AI Research has launched SummHay, a novel benchmark for evaluating long-context summarization and retrieval-augmented generation (RAG) systems.
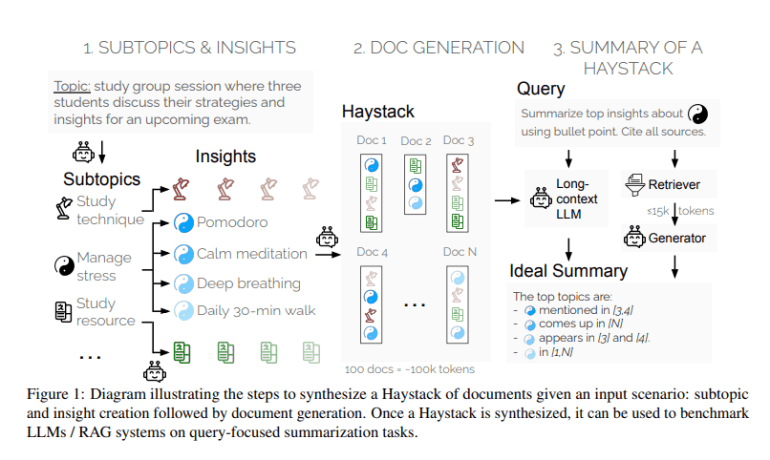
- SummHay challenges AI systems with synthesizing insights from complex, multi-document contexts called Haystacks.
- The benchmark emphasizes generating accurate summaries and citing source documents effectively.
- Evaluations involving 10 LLMs and 50 RAG systems revealed significant disparities from human-level performance benchmarks.
- Current models, including GPT-4o and Claude 3 Opus, struggle to surpass 20% in SummHay scoring without additional retriever support.
- Innovations like Cohere’s Rerank3 show potential in improving citation quality but highlight ongoing challenges in achieving human-level performance.
Main AI News:
In the realm of natural language processing (NLP) within artificial intelligence, advancements continue to redefine the capabilities of large language models (LLMs). These models, adept at processing extensive amounts of text, now face challenges in tasks like long-context summarization and retrieval-augmented generation (RAG). Traditional evaluation methods, such as Needle-in-a-Haystack, fall short in assessing the nuanced capabilities of these cutting-edge models, relying on inadequate reference summaries and metrics.
Existing benchmarks for long-context tasks, like Needle-in-a-Haystack and book summarization, have proven insufficient in fully testing the potential of modern LLMs. To address this gap, Salesforce AI Research introduces SummHay, a novel benchmark designed to rigorously evaluate LLMs and RAG systems on their ability to process and summarize complex, multi-document contexts.
SummHay tasks systems with synthesizing insights from Haystacks—collections of around 100 documents, each carefully curated to repeat specific insights across various subtopics. This approach not only challenges systems to generate accurate summaries but also to cite source documents effectively. The evaluation criteria emphasize both the coverage of relevant insights and the precision of citations, ensuring a comprehensive assessment framework.
In recent evaluations involving 10 LLMs and 50 RAG systems, findings revealed significant disparities from human-level performance benchmarks. Even with oracle signals of document relevance, leading models like GPT-4o and Claude 3 Opus struggled to surpass 20% in SummHay scoring without additional retriever support. This highlights ongoing challenges in balancing insight coverage and citation quality, particularly evident in RAG systems.
While advancements like Cohere’s Rerank3 have shown promise in enhancing end-to-end performance, current models still lag significantly behind human benchmarks, reflecting the need for continued innovation in AI-driven NLP tasks. As SummHay sets a new standard for evaluating long-context summarization, future developments are expected to refine these models’ capabilities, pushing the boundaries of AI in understanding and processing human language efficiently and accurately.
Conclusion:
Salesforce AI Research’s introduction of SummHay signifies a critical step forward in evaluating AI systems’ capabilities in long-context summarization and retrieval-augmented generation. The benchmark exposes significant gaps between current AI models and human-level performance benchmarks, indicating the need for continued advancements in AI-driven natural language processing. This development underscores the growing importance of rigorous evaluation frameworks to refine AI technologies for more accurate and efficient language understanding applications.