
- Adversarial attacks target neural networks by subtly altering data to induce misclassification.
- MALT (Mesoscopic Almost Linearity Targeting) is a new method designed to counter these attacks.
- Developed by researchers at the Weizmann Institute of Science and New York University, MALT reorders target classes based on gradients rather than model confidence.
- It leverages the principle of “mesoscopic almost linearity” to make small, strategic changes in input data.
- MALT’s iterative optimization process ensures efficient generation of adversarial examples until desired misclassification is achieved.
Main AI News:
Researchers from the Weizmann Institute of Science, Israel, and the Center for Data Science, New York University, have introduced a pioneering method known as MALT (Mesoscopic Almost Linearity Targeting) to address the persistent challenge of adversarial attacks on neural networks. These attacks exploit vulnerabilities inherent in machine learning models, particularly neural networks, which can be manipulated into misclassifying subtly altered data. Such vulnerabilities pose significant concerns for the reliability and security of critical applications such as image classification and facial recognition systems used in security.
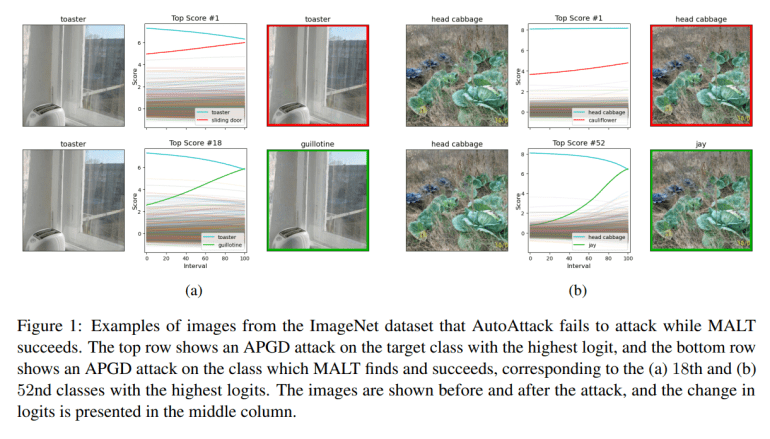
MALT represents a significant leap forward compared to existing methods like AutoAttack, which, while effective, are hindered by their computational intensity and potential oversight of vulnerable classes. Unlike conventional approaches that rely solely on model confidence levels, MALT employs a sophisticated strategy that reorders potential target classes based on normalized gradients. This innovative approach aims to identify classes where minimal modifications can provoke misclassification, thereby optimizing the efficiency and efficacy of adversarial targeting techniques.
Inspired by the concept of “mesoscopic almost linearity,” MALT operates under the hypothesis that neural networks exhibit nearly linear behavior within localized modifications of input data. This conceptual framework simplifies the generation of adversarial examples by treating the decision-making landscape of the model as a flat plane, where targeted alterations can achieve the desired misclassification. Leveraging advanced gradient estimation techniques, MALT iteratively refines modifications to input data, ensuring robust and reliable generation of adversarial examples until the model confidently misclassifies the targeted data.
Conclusion:
The introduction of MALT marks a significant advancement in the defense against adversarial attacks on neural networks. By refining the process of generating adversarial examples based on gradient analysis, MALT enhances the robustness of machine learning systems in critical applications like image classification and security technologies. This innovation underscores the ongoing evolution towards more secure and reliable AI solutions, addressing longstanding concerns about the vulnerability of neural networks to malicious manipulations in real-world scenarios.