
- Transformer architectures face scalability challenges due to linear growth in computational costs with feedforward layer widths.
- Mixture-of-Experts (MoE) models alleviate these challenges by employing sparsely activated expert modules.
- Google DeepMind introduces Parameter Efficient Expert Retrieval (PEER) to optimize MoE models, leveraging a product key technique for efficient retrieval from over a million experts.
- PEER enhances model granularity and decouples computational costs from parameter counts using a learned index structure for routing.
- Experimental results demonstrate PEER’s superiority over dense feedforward layers and coarse-grained MoEs in language modeling tasks, achieving lower perplexity scores across various datasets.
Main AI News:
In the realm of transformer architectures, the costs associated with computational resources and activation memory escalate proportionally to the expansion of feedforward (FFW) layer widths. This scalability challenge presents a formidable hurdle, particularly as models grow more expansive and intricate. Overcoming these obstacles is pivotal for advancing AI research, impacting the practical deployment of large-scale models in domains like language modeling and natural language processing.
Traditional approaches to this challenge hinge on Mixture-of-Experts (MoE) frameworks, deploying sparsely activated expert modules rather than dense FFW layers. This strategy decouples model size from computational costs. Yet, despite the potential demonstrated by researchers such as Shazeer et al. (2017) and Lepikhin et al. (2020), scaling MoE models beyond a limited number of experts poses computational and optimization challenges. Efficiency gains often plateau with increasing model size due to fixed training token constraints, limiting their potential in tasks demanding extensive and continual learning.
Addressing these limitations, researchers at Google DeepMind introduce Parameter Efficient Expert Retrieval (PEER), a novel methodology designed to enhance MoE models’ granularity. Leveraging the product key technique for sparse retrieval from a pool exceeding one million tiny experts, PEER optimizes the performance-compute trade-off. Central to this innovation is a learned index structure for efficient and scalable expert retrieval, decoupling computational costs from parameter counts—a significant leap beyond existing architectures. PEER layers exhibit substantial efficiency and performance improvements, particularly in language modeling tasks.
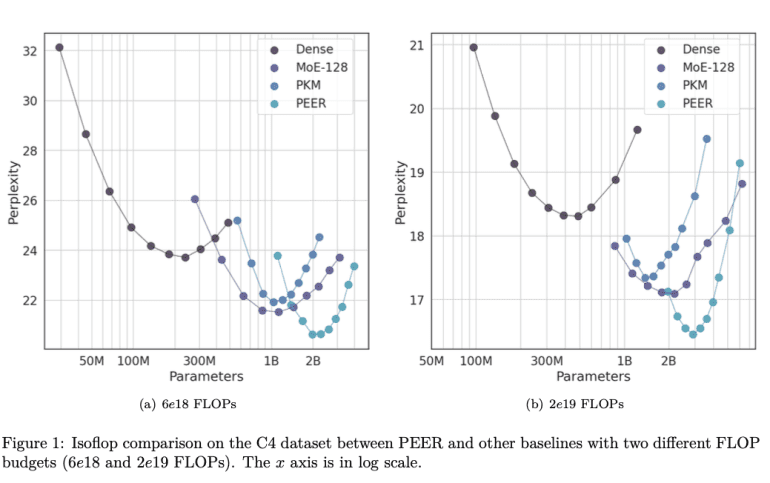
PEER operates by mapping input vectors to query vectors, which are then matched with product keys to retrieve top-k experts—single-neuron multi-layer perceptrons contributing to final outputs via weighted combinations based on router scores. This product key retrieval technique simplifies expert retrieval complexities, enabling efficient management of vast expert pools. Experimental validation on the C4 dataset, utilizing isoFLOP analysis, compared PEER against dense FFW, coarse-grained MoEs, and Product Key Memory (PKM) layers. Configurations varied model sizes and training tokens to identify optimal compute efficiencies.
Results underscore PEER’s superior performance-compute trade-off over dense FFWs and coarse-grained MoEs. Across multiple language modeling datasets—Curation Corpus, Lambada, Pile, Wikitext, and C4—PEER models achieved significantly lower perplexity scores. For instance, under a 2e19 FLOP budget, PEER models attained a perplexity of 16.34 on the C4 dataset, surpassing dense models’ 17.70 and MoE models’ 16.88. These findings underscore PEER’s efficiency and effectiveness in scaling transformer model performance.
Conclusion:
Google DeepMind’s PEER methodology represents a significant advancement in transformer architecture, addressing critical scalability issues and enhancing efficiency in large-scale AI applications. This innovation could potentially redefine benchmarks for performance-compute trade-offs in the market, offering more scalable and cost-effective solutions for language modeling and related tasks.