
- Evaluating large language models (LLMs) is challenging due to their complexity and traditional metrics like BLEU and ROUGE falling short.
- Google DeepMind, Google, and UMass Amherst have introduced FLAMe, a family of Foundational Large Autorater Models for enhanced LLM evaluation.
- FLAMe is trained using over 5 million human judgments from more than 100 quality assessment tasks, employing supervised multitask fine-tuning for effective transfer learning.
- The FLAMe-RM variant, fine-tuned for reward modeling, demonstrates significant improvements in performance over models like GPT-4 and Claude-3.
- FLAMe models outperform existing LLMs on 8 out of 12 automated evaluation benchmarks.
- FLAMe-Opt-RM offers computational efficiency with a novel fine-tuning strategy, achieving competitive results with significantly fewer training data points.
Main AI News:
As large language models (LLMs) evolve, evaluating their performance has become increasingly complex. The need for reliable and consistent evaluation methods is critical for advancing AI technologies. Traditional evaluation metrics, such as BLEU and ROUGE, which focus primarily on lexical overlaps, fall short in capturing the nuanced quality of LLM outputs. Recent methods have attempted to address this by using pretrained models to measure distributional similarity, but issues with generalizability and consistency remain. The high costs and time demands of human evaluations further complicate large-scale assessments.
In response to these challenges, a collaborative team from Google DeepMind, Google, and UMass Amherst has introduced FLAMe, a family of Foundational Large Autorater Models designed to revolutionize LLM evaluation. FLAMe harnesses a comprehensive set of quality assessment tasks derived from human judgments to train and standardize autoraters. With training based on over 5 million human judgments across more than 100 quality assessment tasks, FLAMe uses supervised multitask fine-tuning to achieve effective transfer learning. This robust approach enables FLAMe to outperform established models like GPT-4 and Claude-3.
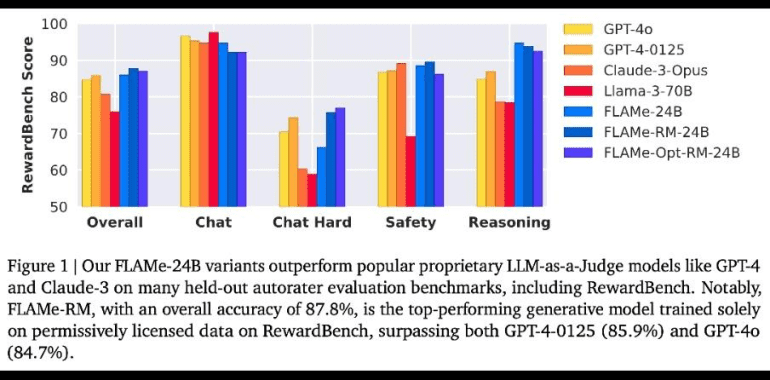
The development of FLAMe involved a rigorous data collection and standardization process. Human evaluations from past studies were curated and reformatted into a unified text-to-text format, with each task converted into input-target pairs. This methodology ensures that FLAMe learns robust human judgment patterns while minimizing the impact of noisy data. Notably, the FLAMe-RM variant, tailored for reward modeling evaluation, showcases significant performance improvements. Fine-tuned with a blend of four datasets covering chat, reasoning, and safety, FLAMe-RM demonstrates marked advancements in evaluation accuracy.
FLAMe’s performance is impressive across multiple benchmarks. The FLAMe-RM-24B model, optimized for reward modeling, achieved an accuracy of 87.8% on RewardBench, outpacing both GPT-4-0125 (85.9%) and GPT-4o (84.7%). On the CoBBLEr bias benchmark, FLAMe shows considerably lower bias compared to other autorater models. Additionally, FLAMe outperforms existing LLMs on 8 out of 12 automated evaluation benchmarks, covering a range of quality assessment tasks such as summary comparisons and factual accuracy evaluations.
The FLAMe-Opt-RM variant offers computational efficiency by utilizing a novel tail-patch fine-tuning strategy. By fine-tuning the initial PaLM-2-24B checkpoint on an optimized mixture for 5000 steps, this model achieves competitive RewardBench performance with about 25 times fewer training data points. This research underscores the potential for further performance improvements with extended training, highlighting FLAMe-Opt-RM as a versatile and efficient evaluation tool.
Conclusion:
The introduction of FLAMe by Google AI represents a significant advancement in the evaluation of large language models. By addressing the limitations of traditional metrics and leveraging a vast dataset of human judgments, FLAMe sets a new standard for evaluating LLM performance. This innovation has implications for the market by potentially reducing the costs and time associated with LLM evaluations and improving the accuracy and reliability of assessments. As a result, organizations investing in AI and LLM technologies can expect more consistent and actionable insights, driving further advancements and applications in the AI field.