
- Amazon researchers unveil a new exam-based evaluation method for Retrieval-Augmented Generation (RAG) systems.
- The fully automated approach measures factual accuracy without needing a pre-annotated dataset.
- The method focuses on model performance factors such as size, retrieval techniques, and fine-tuning.
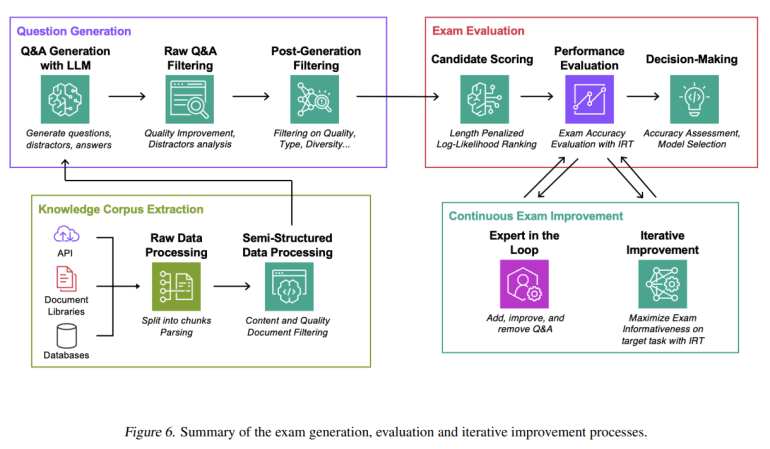
- Automated exams created by LLMs assess RAG systems through multiple-choice questions.
- The approach balances evaluation representativeness with scoring simplicity for effective knowledge assessment.
- Item Response Theory (IRT) is used to enhance test informativeness for task-specific performance.
- Four diverse datasets are provided for benchmark evaluation: AWS DevOps manuals, Arxiv abstracts, StackExchange queries, and SEC filings.
Main AI News:
Recent advancements in Large Language Models (LLMs) have elevated their popularity, yet evaluating their performance across diverse tasks remains a complex challenge. Traditional public standards often fall short in reflecting the LLMs’ proficiency, particularly for tasks requiring specialized domain knowledge. Current evaluation metrics capture various performance aspects, but no single measure provides a comprehensive assessment.
To address this, Amazon researchers have introduced a novel exam-based evaluation approach for Retrieval-Augmented Generation (RAG) systems. This fully automated method does not rely on a pre-annotated ground truth dataset, focusing instead on factual accuracy—the system’s ability to retrieve and apply precise information to answer user queries. This approach offers a deeper understanding of factors affecting RAG performance, including model size, retrieval techniques, prompting strategies, and fine-tuning methods, while aiding in the selection of optimal components for RAG systems.
The researchers have developed a scalable, quantitative evaluation technique, diverging from traditional human-in-the-loop methods that are often expensive due to the need for expert involvement. The automated exams are created by an LLM using relevant data, and candidate RAG systems are evaluated based on their responses to multiple-choice questions derived from these exams.
This approach ensures effective and consistent evaluation of factual knowledge by balancing representativeness with scoring simplicity. Exam results highlight areas for improvement, facilitating continuous, feedback-driven enhancements to the exam corpus.
Additionally, the team has released a methodological enhancement plan for the automated exam-generation process. The generated tests are optimized with Item Response Theory (IRT) to increase their informativeness regarding task-specific model performance. Demonstrating the versatility of this method, the team applied it across four knowledge domains—AWS DevOps troubleshooting manuals, Arxiv abstracts, StackExchange queries, and SEC filings—showcasing its adaptability and efficacy.
The primary contributions of the research are:
- Introduction of a comprehensive automated assessment approach for RAG LLM pipelines using task-specific synthetic tests tailored to each assignment’s needs.
- Utilization of Item Response Theory (IRT) to create reliable, understandable assessment metrics that clarify model performance and effectiveness.
- Proposal of a systematic, fully automated test creation method, featuring iterative refinement to enhance exam informativeness and accuracy.
- Provision of benchmark datasets for evaluating RAG systems through four diverse tasks, based on publicly available datasets from various fields.
This innovative approach marks a significant advancement in the evaluation of Retrieval-Augmented Generation systems, promising more precise and scalable assessments of LLM performance.
Conclusion:
The introduction of Amazon’s automated, exam-based evaluation method represents a significant advancement in assessing Retrieval-Augmented Generation systems. This approach not only improves the accuracy and efficiency of evaluating LLMs but also offers a scalable solution that reduces reliance on costly human evaluations. By utilizing Item Response Theory and diverse datasets, this method ensures a comprehensive understanding of model performance, potentially setting a new standard for performance evaluation in the AI industry. This development is likely to influence market dynamics by encouraging broader adoption of automated evaluation techniques and driving innovations in LLM assessment practices.