
- LaMMOn is an end-to-end multi-camera tracking model developed by researchers from the University of Tennessee at Chattanooga and the L3S Research Center.
- Utilizes transformers and graph neural networks to enhance tracking capabilities.
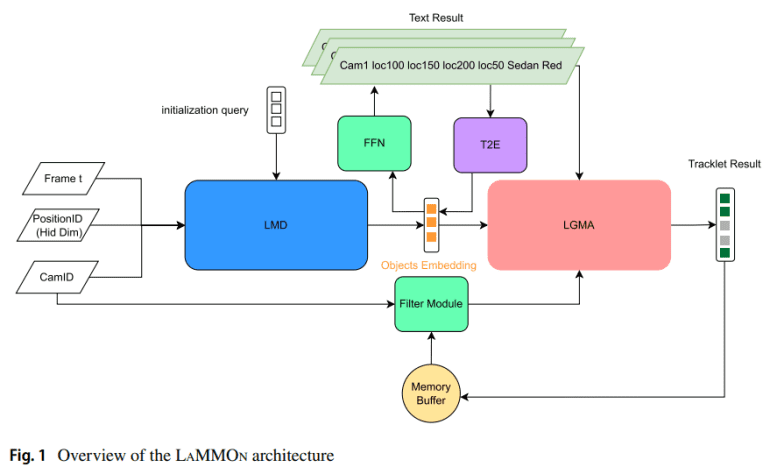
- Integrates three modules: Language Model Detection (LMD) for object detection, Language and Graph Model Association (LGMA) for tracking and clustering, and Text-to-Embedding (T2E) for generating object embeddings from text.
- Demonstrates competitive performance on datasets such as CityFlow and TrackCUIP with efficient real-time processing speeds.
- Addresses challenges in multi-target multi-camera tracking (MTMCT) by eliminating the need for new matching rules and extensive manual labeling.
- LaMMOn outperforms existing methods in IDF1, HOTA, and Recall scores on various datasets, showcasing its effectiveness in improving tracking accuracy and efficiency.
Main AI News:
The integration of multi-target multi-camera tracking (MTMCT) in intelligent transportation systems is crucial yet fraught with challenges due to data scarcity and labor-intensive annotation processes. Advances in computer vision have improved traffic management, providing enhanced prediction and analysis of traffic volumes. MTMCT encompasses tracking vehicles across multiple cameras, involving object detection, intra-camera multi-object tracking, and trajectory clustering to create comprehensive global vehicle movement maps. However, issues persist, including the necessity for new matching rules, limited datasets, and the high cost of manual labeling.
A groundbreaking solution, LaMMOn, has been developed by researchers from the University of Tennessee at Chattanooga and the L3S Research Center at Leibniz University Hannover. This end-to-end multi-camera tracking model utilizes transformers and graph neural networks, incorporating three primary modules: Language Model Detection (LMD) for object detection, Language and Graph Model Association (LGMA) for tracking and clustering, and Text-to-Embedding (T2E) for generating object embeddings from text to overcome data limitations. LaMMOn excels across various datasets such as CityFlow and TrackCUIP, delivering competitive results with efficient real-time processing speeds. By leveraging synthesized text embeddings, LaMMOn eliminates the need for new matching rules and extensive manual labeling.
In the realm of Multi-Object Tracking (MOT), which involves tracking objects within single-camera video frames to create tracklets, methods like Tracktor, CenterTrack, and TransCenter have significantly advanced tracking capabilities. MTMCT extends these methods by integrating object movements across multiple cameras, often enhancing MOT results with clustering techniques. Although spatial-temporal filtering and traffic law constraints have improved accuracy, LaMMOn stands out by combining detection and association tasks into a unified end-to-end framework. Utilizing transformers such as Trackformer and TransTrack, along with graph neural networks like GCN and GAT, LaMMOn enhances tracking performance, adeptly handling complex data structures and optimizing multi-camera tracking.
LaMMOn’s framework is distinguished by its three core modules: LMD for object detection and embedding generation, LGMA for multi-camera tracking and trajectory clustering, and T2E for creating synthetic embeddings from text. The LMD module integrates video frame inputs with positional and camera ID embeddings, employing Deformable DETR for object embedding. LGMA utilizes these embeddings for global tracklist association through graph-based token features, while the T2E module, based on Sentencepiece, produces synthetic embeddings to mitigate data limitations and reduce labeling costs.
Evaluated across three MTMCT datasets—CityFlow, I24, and TrackCUIP—LaMMOn demonstrated impressive performance. On CityFlow, it achieved an IDF1 score of 78.83% and a HOTA score of 76.46% with 12.2 FPS, outperforming methods like TADAM and BLSTM-MTP. For the I24 dataset, LaMMOn delivered a HOTA of 25.7 and a Recall of 79.4, showcasing superior performance. TrackCUIP results further highlight LaMMOn’s effectiveness, with 4.42% improvements in IDF1 and 2.82% in HOTA over baseline methods, while maintaining an efficient FPS.
Conclusion:
LaMMOn’s advanced use of transformers and graph neural networks represents a significant leap forward in multi-camera tracking technology. By integrating object detection, tracking, and embedding generation into a cohesive framework, LaMMOn addresses critical challenges in traffic management and multi-camera tracking. Its ability to achieve high accuracy and efficiency while reducing the need for manual data labeling positions it as a valuable tool for intelligent transportation systems and related applications. This development highlights the growing importance of AI-driven solutions in enhancing real-time tracking capabilities and suggests a broader trend towards more integrated and automated systems in the transportation and security sectors.