
- The Long-form RobustQA (LFRQA) dataset introduces comprehensive, human-written long-form answers integrating information from multiple documents.
- Spanning 26,000 queries across seven domains, LFRQA evaluates the cross-domain generalization of retrieval-augmented generation (RAG) QA systems.
- LFRQA is designed to address the limitations of current single-source and extractive QA datasets.
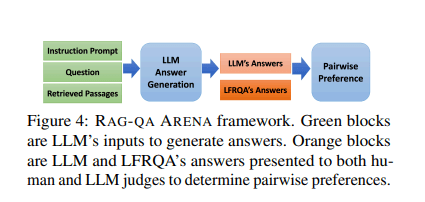
- The RAG-QA Arena framework uses LFRQA to benchmark QA systems by comparing LLM-generated answers with human-written responses.
- Performance results show only 41.3% of top LLM answers were preferred over LFRQA answers, with a high correlation of 0.82 between model-based and human evaluations.
- LFRQA answers, including information from up to 80 documents, were preferred in 59.1% of cases.
- A 25.1% performance gap between in-domain and out-of-domain data highlights the importance of cross-domain evaluation.
- LFRQA includes metrics on document usage, answer coherence, and fluency to guide QA system improvements.
Main AI News:
Question answering (QA) has emerged as a vital component in natural language processing (NLP), concentrating on developing systems that can effectively retrieve and generate responses from extensive datasets. Retrieval-augmented generation (RAG) enhances the precision and relevance of responses by merging information retrieval with text generation, thus eliminating irrelevant data and presenting only the most pertinent content for large language models (LLMs) to formulate answers.
A primary issue with current QA evaluations is their narrow focus, often limited to single-source datasets or short, extractive answers. This restricts the ability to assess how well LLMs perform across diverse domains. Existing methods like Natural Questions and TriviaQA predominantly use Wikipedia or web documents, which fall short for evaluating cross-domain effectiveness. This gap underscores the urgent need for more robust evaluation frameworks that test QA systems’ adaptability across various domains.
To tackle these challenges, a team from AWS AI Labs, Google, Samaya.ai, Orby.ai, and the University of California, Santa Barbara, has introduced the Long-form RobustQA (LFRQA) dataset. LFRQA features human-generated long-form answers that weave information from multiple documents into coherent narratives. Spanning 26,000 queries across seven domains, this dataset is designed to test LLM-based RAG-QA systems’ generalization across different fields.
LFRQA differentiates itself from prior datasets by providing long-form answers based on a well-rounded corpus, ensuring coherence and broad domain coverage. It includes annotations from diverse sources, making it a valuable benchmarking tool for QA systems. This new dataset addresses the limitations of extractive QA datasets, which often lack the depth and detail required for modern LLM evaluations.
The research team also developed the RAG-QA Arena framework to utilize LFRQA for assessing QA systems. This framework uses model-based evaluators to compare LLM-generated responses with human-written answers from LFRQA. By focusing on long-form, coherent responses, RAG-QA Arena offers a more accurate and challenging benchmark for QA systems. The extensive experiments showed a strong correlation between model-based and human evaluations, validating the framework’s efficacy.
To ensure high-quality results, LFRQA was meticulously curated. Annotators combined short answers into long-form responses and included additional relevant information from source documents. Rigorous quality control measures, including random audits, ensured completeness, coherence, and relevance. This careful process resulted in a dataset that robustly benchmarks cross-domain QA system performance.
Performance insights from the RAG-QA Arena reveal significant findings. Only 41.3% of responses from top-performing LLMs were preferred over LFRQA’s human-written answers. The dataset demonstrated a high correlation coefficient of 0.82 between model-based and human evaluations. Additionally, LFRQA answers, which included information from up to 80 documents, were favored in 59.1% of cases over leading LLM answers. The framework also highlighted a 25.1% performance gap between in-domain and out-of-domain data, underscoring the importance of cross-domain evaluation in developing resilient QA systems.
Beyond its comprehensive approach, LFRQA includes detailed performance metrics, offering valuable insights into QA system effectiveness. It provides data on the number of documents used, answer coherence, and fluency, helping researchers identify strengths and areas for improvement in various QA methodologies.
Conclusion:
The introduction of the Long-form RobustQA (LFRQA) dataset and RAG-QA Arena framework marks a significant advancement in the evaluation of question-answering systems. By addressing the limitations of current evaluation methods and providing a more comprehensive benchmark, these innovations offer a deeper understanding of cross-domain performance. This shift is crucial for developers aiming to enhance the robustness and adaptability of their QA systems. The ability to measure and compare the effectiveness of LLMs across various domains will drive improvements in AI-driven solutions, making them more versatile and reliable for diverse applications.