
- Nvidia has released the Minitron 4B and 8B, a new series of large language models.
- These models use advanced pruning and knowledge distillation techniques to achieve up to 40x faster training.
- LLMs traditionally require significant computational resources and extensive datasets, which are costly and challenging to scale.
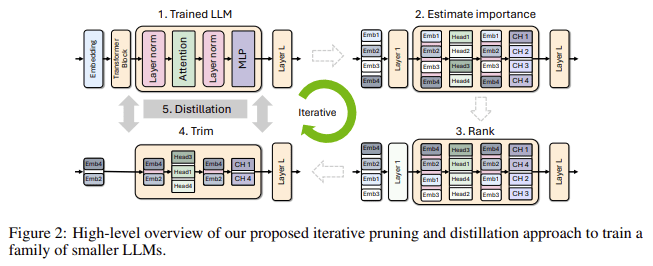
- Nvidia’s method includes structured pruning, removing less important model components, and knowledge distillation, transferring knowledge from larger models to smaller ones.
- The Minitron models reduce the size of the original models by 2-4x while maintaining performance.
- The 8B and 4B models require up to 40x fewer training tokens and offer a 1.8x reduction in training costs.
- The 8B model shows a 16% improvement in MMLU scores compared to models trained from scratch.
- The Minitron models are now available on Huggingface, providing efficient options for AI researchers and practitioners.
Main AI News:
Nvidia has unveiled its new Minitron model series, featuring the 4B and 8B variants, promising to revolutionize the efficiency of training large language models (LLMs). These models leverage advanced pruning and knowledge distillation techniques to achieve training speeds up to 40 times faster than traditional methods. LLMs, critical for applications in machine translation, sentiment analysis, and conversational AI, typically require immense computational resources and extensive datasets, posing significant challenges in terms of cost and scalability.
Addressing these challenges, Nvidia’s researchers have developed a novel approach that significantly reduces the computational demands of LLMs. Their method involves structured pruning, which systematically removes less important components such as neurons, layers, or attention heads from a pre-trained model. This is combined with knowledge distillation, where knowledge is transferred from a larger, more complex model to a smaller, more efficient one, preserving performance while reducing resource requirements.
The Minitron models start with a large pre-trained base, which is then pruned to create smaller, more manageable variants. The importance of each model component is assessed through activation-based metrics on a calibration dataset, with less critical elements being removed. The pruned model is then retrained using a reduced dataset, thanks to the knowledge distillation process, which helps recover accuracy while significantly cutting down training costs and time.
In testing, the Minitron-4 series demonstrated a 2-4× reduction in model size without compromising performance. The 8B and 4B models, derived from a 15B base model, needed up to 40× fewer training tokens, resulting in a 1.8× reduction in training costs for the entire model range. The 8B model, in particular, showed a 16% improvement in MMLU scores compared to models trained from scratch, outperforming other leading models such as Mistral 7B and LLaMa-3 8B. The Minitron models are now available on Huggingface, providing the AI community with access to these optimized, efficient models.
This breakthrough positions Nvidia at the forefront of AI model training efficiency, making high-performance LLMs more accessible and cost-effective for researchers and practitioners alike.
Conclusion:
Nvidia’s introduction of the Minitron 4B and 8B models marks a significant advancement in AI model training efficiency. By achieving up to 40 times faster training through innovative pruning and distillation techniques, Nvidia is addressing the high costs and resource demands associated with large language models. This development will likely reduce barriers to scaling and deploying advanced AI technologies, making powerful models more accessible and affordable for a broader range of users. The increased efficiency and cost savings presented by the Minitron models position Nvidia as a leader in optimizing AI training processes, potentially reshaping market dynamics and driving further innovation in the field.