
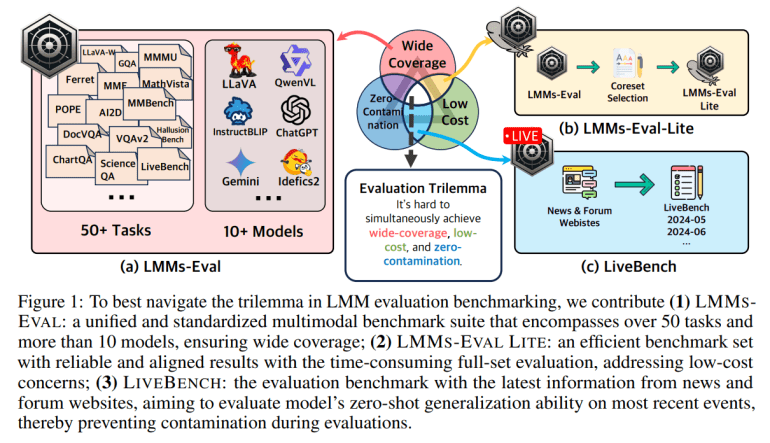
- LMMS-EVAL introduces a unified benchmark framework for assessing multimodal AI models.
- The framework evaluates over ten models and 30 variants across more than 50 tasks.
- Provides a standardized interface for integrating new models and datasets, ensuring consistent evaluations.
- Addresses the challenge of the “impossible triangle” with cost-effective and comprehensive evaluation solutions.
- LMMS-EVAL LITE offers a streamlined, affordable alternative while maintaining high evaluation quality.
- LiveBench provides a dynamic approach using current data from news and forums for real-time benchmarking.
Main AI News:
In the rapidly evolving landscape of artificial intelligence, large language models (LLMs) like GPT-4, Gemini, and Claude have achieved remarkable benchmarks, sometimes surpassing human capabilities. As these models continue to advance, the need for effective evaluation tools becomes crucial to differentiate between various models and identify their specific strengths and weaknesses. The field of AI evaluation is shifting from a solely language-focused approach to encompass multiple modalities, demanding a more integrated and standardized assessment framework.
Currently, the evaluation of AI models lacks a comprehensive and uniform approach. Instead, developers often rely on custom evaluation pipelines that vary in their data preparation methods, output post-processing techniques, and metrics calculations. This inconsistency creates challenges in ensuring that evaluations are both transparent and reproducible. To address these issues, the LMMs-Lab Team and S-Lab at NTU Singapore have developed LMMS-EVAL, a cutting-edge benchmark framework designed to provide a standardized and reliable evaluation of multimodal models.
LMMS-EVAL stands out by offering a unified evaluation suite that covers over ten multimodal models and approximately 30 variants, spanning more than 50 distinct tasks. The framework is built with a standardized interface that facilitates the integration of new models and datasets, ensuring a cohesive evaluation process. By providing a consistent assessment pipeline, LMMS-EVAL promotes transparency and reproducibility in evaluating model performance across various modalities.
Achieving a benchmark that is cost-effective, comprehensive, and free from contamination remains a significant challenge, often referred to as the “impossible triangle.” While platforms like the Hugging Face OpenLLM leaderboard offer affordable assessments across diverse tasks, they are susceptible to issues such as contamination and overfitting. Conversely, rigorous evaluations, such as those conducted by LMSys Chatbot Arena and AI2 WildVision, require extensive human input, making them costly.
In response to these challenges, LMMS-EVAL introduces two additional components: LMMS-EVAL LITE and LiveBench. LMMS-EVAL LITE provides a streamlined evaluation method that focuses on key tasks and eliminates superfluous data instances, offering a cost-effective yet comprehensive evaluation solution. This version maintains high evaluation quality while reducing expenses, making it an appealing alternative to more detailed assessments.
LiveBench, on the other hand, presents a dynamic approach to benchmarking by utilizing up-to-date information from news sources and online forums. This method assesses models’ zero-shot generalization capabilities on current events, offering a low-cost and broadly applicable means of evaluating performance in real-time scenarios. By leveraging recent data, LiveBench ensures that models remain relevant and accurate in the face of ever-changing real-world conditions.
Conclusion:
LMMS-EVAL marks a significant advancement in AI evaluation by providing a standardized and comprehensive framework for multimodal models. By addressing the inconsistencies in current evaluation practices and offering cost-effective solutions through LMMS-EVAL LITE and LiveBench, this framework sets a new industry standard. It enables more transparent, reproducible, and relevant assessments, which can enhance model development and deployment across various applications. This approach not only improves the reliability of AI evaluations but also supports the broader adoption of multimodal AI technologies in diverse real-world scenarios.