
- Transformer models have advanced NLP capabilities but face challenges with memory management for large-scale training.
- Traditional methods like multi-query attention and grouped query attention reduce memory usage during inference but struggle with growing model complexities.
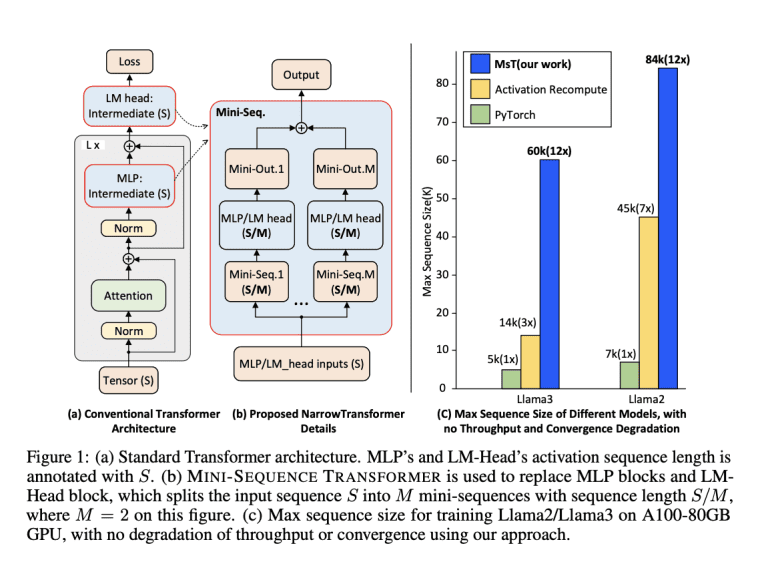
- The MINI-SEQUENCE TRANSFORMER (MST) introduces an approach that processes input sequences as mini-sequences, significantly reducing memory usage.
- MST uses activation recomputation to optimize memory in both forward and backward passes, requiring minimal code changes for integration.
- MST’s iterative processing reduces memory footprint and improves efficiency for training models like Llama3-8B.
- The method also scales well in distributed settings when combined with DeepSpeed-Ulysses, maintaining compatibility with sequence parallelism techniques.
- Experiments show MST improves sequence length capabilities up to 60k with substantial performance gains over standard methods.
- MST demonstrates scalability with linear sequence length increase relative to the number of GPUs, optimizing memory use with minimal execution time impact.
Main AI News:
The advancement of Transformer models has dramatically enhanced natural language processing (NLP) by elevating performance and capabilities. However, this rapid progress brings significant challenges, particularly in managing the memory requirements for training these expansive models. As Transformers increase in size and complexity, effectively handling memory demands becomes crucial. A new paper tackles this issue with a novel approach to optimize memory usage without sacrificing long-sequence training performance.
Traditional methods, such as multi-query attention and grouped query attention (GQA), have improved memory efficiency during inference by optimizing key-value cache size. These techniques have been successfully applied in large-scale models like PaLM and LLaMA. Nevertheless, ongoing architectural improvements, such as the expanded vocabulary and intermediate layers in Llama3, exacerbate memory challenges during training.
To address these issues, researchers from Caltech and CMU propose the MINI-SEQUENCE TRANSFORMER (MST). MST offers a solution by partitioning input sequences and processing them iteratively as mini-sequences. This method significantly cuts down on intermediate memory usage through activation recomputation—a technique that recalculates activations of certain layers during the backward pass, conserving memory throughout both forward and backward passes. MST is designed for seamless integration with existing training frameworks, requiring minimal code adjustments while maintaining high efficiency and accuracy for lengthy sequences.
By partitioning sequences into smaller chunks, MST effectively reduces memory consumption during model training. For example, in Llama3-8B training, memory allocated for activations in the forward pass is significant, with similar challenges in the backward pass. MST’s approach of processing mini-sequences iteratively addresses this issue, optimizing memory for gradients and optimizer states to enhance training efficiency.
The MST approach is also adaptable to distributed settings. When combined with DeepSpeed-Ulysses, MST segments the input tensor along the sequence dimension, enabling parallel computation across multiple GPUs. This segmentation, along with activation recomputation, substantially reduces activation memory needs. The distributed MST maintains compatibility with various sequence parallelism techniques like Megatron-LM and Ring Attention, ensuring scalability and flexibility across diverse training environments.
Extensive experiments confirm MST’s effectiveness. The method enabled Llama3-8B training with a context length of up to 60k on a single A100 GPU, showing a 12 to 20 times improvement in sequence length over standard implementations. Additionally, MST maintained equivalent training throughput compared to traditional long-sequence methods, confirming that the optimization does not compromise performance.
The evaluation also demonstrates MST’s scalability in distributed settings. Leveraging DeepSpeed-Ulysses, MST scales sequence length linearly with the number of GPUs, showcasing its potential for large-scale applications. The memory optimization, particularly for the LM-Head component, achieved substantial reductions in memory usage with minimal impact on execution time for extended sequences.
Conclusion:
The introduction of MINI-SEQUENCE TRANSFORMER (MST) represents a significant advancement in optimizing memory usage for large-scale NLP models. By partitioning sequences into mini-sequences and utilizing activation recomputation, MST addresses critical memory challenges, enhancing training efficiency and scalability. This innovation is poised to benefit organizations involved in training extensive Transformer models by enabling more effective resource management and improved performance. As NLP models continue to grow in complexity, MST’s approach will likely become a crucial tool for maintaining efficiency and managing the increasing demands of model training.