
- Lawrence Livermore National Laboratory critically examines the trustworthiness of large language models (LLMs).
- Despite their potential, LLMs trained on vast datasets are not inherently trustworthy.
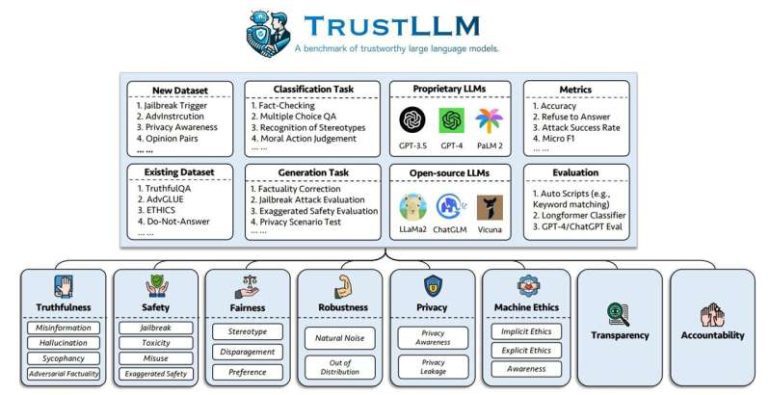
- The “TrustLLM” framework evaluates 16 leading LLMs across eight dimensions of trustworthiness.
- Results show that current LLMs have mixed performance, with no model meeting all trustworthiness standards.
- Research also explores the impact of model compression on trustworthiness, revealing that some methods can improve performance while others can degrade it.
- The findings are crucial in the context of AI safety, as highlighted by recent governmental directives.
Main AI News:
As the surge in large language models (LLMs) reshapes the AI landscape, researchers at Lawrence Livermore National Laboratory are investigating the reliability of these advanced systems. While LLMs hold transformative potential—from cybersecurity to autonomous research—the question remains: Can we truly trust their outputs?
LLMs, the powerhouse behind generative AI, are trained on vast datasets to craft responses to user queries. Despite their promise to accelerate scientific endeavors, the sheer volume of data doesn’t automatically equate to trustworthy results. Questions about data quality, biases, and error detection loom large. Notably, even smaller models can sometimes outperform their larger counterparts, raising concerns about the reliability and standards of LLMs.
Livermore’s Bhavya Kailkhura, in collaboration with global researchers, has co-authored two pivotal papers accepted at the 2024 International Conference on Machine Learning to address these challenges. The first paper, “TrustLLM: Trustworthiness in Large Language Models,” offers a comprehensive evaluation framework for LLM trustworthiness, scrutinizing 16 leading models, including ChatGPT, Vicuna, and Llama2. Their findings, published on the arXiv preprint server, reveal a complex landscape where trustworthiness across eight critical dimensions—fairness, machine ethics, privacy, robustness, safety, truthfulness, accountability, and transparency—varies significantly.
The TrustLLM framework delves into each dimension, highlighting where current LLMs fall short. For instance, fairness is measured by a model’s ability to avoid discriminatory outputs, while machine ethics assess its alignment with human morals. The team’s research uncovered mixed results: while most models adhered to privacy policies, their performance on tasks like stereotype detection and handling unexpected data was inconsistent.
The study’s broader implications are significant. Despite advancements, none of the evaluated models met the full trustworthiness criteria set by TrustLLM. However, this research illuminates areas for improvement, pushing the AI community to prioritize trustworthiness as these models evolve.
In parallel, another paper from Kailkhura’s team explores LLM trustworthiness in the context of model compression—a process essential for enhancing computational efficiency. Compressing a model can reduce its size and speed up response times, but it also risks compromising trustworthiness. The team’s findings, published on arXiv, reveal that compression methods like quantization can sometimes improve trust metrics, while others, like pruning, may degrade performance. Striking the right balance is vital, as excessive compression leads to diminishing returns in trustworthiness.
Livermore’s ongoing LLM research is crucial, especially in light of the October 2023 White House Executive Order emphasizing AI safety. The Laboratory Directed Research and Development program continues to fund projects to maximize AI’s benefits while mitigating risks. For Kailkhura and his colleagues, the mission is clear: refining LLMs to be both powerful and trustworthy is an objective and a necessity in today’s rapidly advancing AI landscape.
Conclusion:
The research conducted by Lawrence Livermore National Laboratory highlights the growing need for reliable and trustworthy AI models in the market. As LLMs become increasingly integral to various industries, the market must anticipate a more robust demand for models that perform efficiently and adhere to stringent trustworthiness standards. This focus on AI safety, driven by research findings and governmental directives, will likely steer the industry toward more rigorous development practices. Companies that prioritize and invest in trustworthiness in their AI offerings will be better positioned to lead in an environment where AI safety and reliability are paramount. This shift will also likely spur innovation in compression techniques that enhance model efficiency without compromising integrity, further shaping the competitive landscape in the AI market.