

TL;DR:
- MPT-7B is a cutting-edge pretrained transformer model introduced by MosaicML Foundations.
- It offers performance-optimized layer implementations, greater training stability, and no limitations on context length.
- Trained from scratch on a massive 1 trillion tokens of text and code within 9.5 days.
- MPT-7B is open-source, licensed for commercial use, and provides significant improvements for businesses and organizations.
- The model outperforms other open-source 7B-20B models and matches the quality of LLaMA-7B.
- MosaicML Foundations has also released fine-tuned models for instruction following, chatbot dialogue generation, and long-context story writing.
- MPT-7B’s construction involved meticulous data preparation, training, and fine-tuning processes.
- It enables organizations to build custom LLMs and leverage predictive analytics for decision-making processes.
- MPT-7B’s availability on the MosaicML platform empowers organizations to enhance efficiency, privacy, and cost transparency in training LLMs.
Main AI News:
The rapidly evolving landscape of Large Language Models (LLMs) is creating quite a stir. However, for organizations lacking the necessary resources, it can be a daunting task to ride the wave of these powerful models. Training and deploying LLMs can be intricate, leaving some feeling excluded. Thankfully, open-source LLMs, such as the LLaMA series developed by Meta, have paved the way for accessible LLM resources.
Introducing MosaicML Foundations’ latest addition to their series – MPT-7B.
What sets MPT-7B apart?
MPT stands for MosaicML Pretrained Transformer. MPT models are decoder-only transformers in the GPT-style, boasting a range of enhancements:
- Performance-optimized layer implementations
- Greater training stability through architectural modifications
- No limitations on context length
MPT-7B, a transformer model trained from scratch using a staggering 1 trillion tokens of text and code, takes center stage. Yes, you read that right – 1 TRILLION! This feat was accomplished within a mere 9.5 days, entirely driven by the MosaicML platform and requiring zero human intervention. The training process incurred a cost of approximately $200,000 for MosaicML.
This groundbreaking model is open-source, enabling its use in commercial applications. MPT-7B promises to revolutionize how businesses and organizations leverage predictive analytics and enhance their decision-making processes. Let’s delve into the key features of MPT-7B:
• Licensed for commercial use • Trained on an extensive dataset comprising 1 trillion tokens • Equipped to handle inputs of extreme length • Optimized for swift training and inference • Boasts highly efficient open-source training code
MPT-7B serves as the foundation model, outperforming other open-source 7B – 20B models currently available. Its quality matches that of LLaMA-7B. To evaluate MPT-7B’s prowess, MosaicML Foundation meticulously devised and executed 11 open-source benchmarks, employing industry-standard evaluation methodologies.
In addition to MPT-7B, MosaicML Foundations has also introduced three fine-tuned models to cater to specific needs:
- MPT-7B-Instruct. The MPT-7B-Instruct model specializes in short-form instruction following. With a staggering 26,834 instructions as of May 14th, MPT-7B-Instruct facilitates quick and concise question-and-answer interactions. If you seek a simple answer to a question, MPT-7B-Instruct is your go-to solution. What sets it apart is its ability to treat input as explicit instructions, enabling the model to generate outputs aligned with the provided instructions.
- MPT-7B-Chat. Yes, another chatbot joins the ranks – MPT-7B-Chat, a dialogue generation model. Whether you desire a conversational speech or a tweet that captures the essence of a paragraph from an article, MPT-7B-Chat excels at generating engaging and seamless multi-turn interactions. Its versatility makes it a valuable asset for a range of conversational tasks.
- MPT-7B-StoryWriter-65k+.Calling all storytellers! MPT-7B-StoryWriter-65k+ caters to those seeking to craft narratives with extensive context. This model, fine-tuned based on MPT-7B, is designed to handle contexts as long as 65,000 tokens, and it can even extrapolate beyond that threshold. MosaicML Foundation achieved an impressive feat by generating 84,000 tokens using a single node equipped with 8xA100-80GB GPUs. This offering sets MPT-7B-StoryWriter-65k+ apart from most open-source LLMs, which typically have limitations on sequences of only a few thousand tokens.
Digging Deeper into MPT-7B’s Construction
The MosaicML team accomplished the development of these models within a remarkably short span of a few weeks. This undertaking encompassed various stages, including data preparation, training, fine-tuning, and deployment. The data used for training was sourced from multiple outlets, each contributing a billion tokens, ultimately resulting in a collective billion effective tokens across all sources. By utilizing EleutherAI’s GPT-NeoX and 20B tokenizer, the team achieved a diverse mix of data, consistent space delimitation, and more.
All MPT-7B models were trained on the MosaicML platform, leveraging A100-40GB and A100-80GB GPUs provided by Oracle Cloud. If you yearn for further insights into the tools and costs associated with MPT-7B, we recommend perusing the comprehensive MPT-7B Blog.
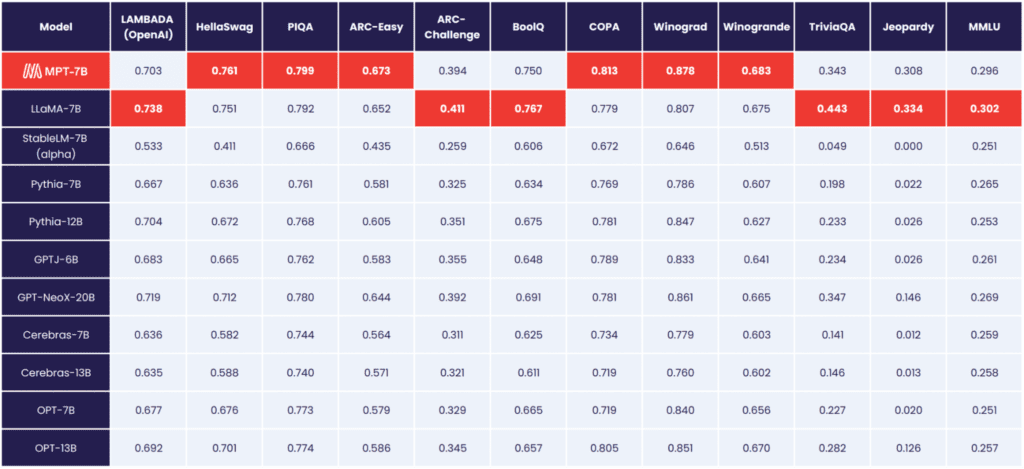
Source: MosaicML Foundation
Conlcusion:
The introduction of MPT-7B, an open-source pretrained transformer model, marks a significant milestone in the market. Organizations now have access to cutting-edge language models with no context length limitations, optimized performance, and commercial licensing. This development empowers businesses to improve their predictive analytics capabilities and decision-making processes, leading to enhanced efficiency and cost transparency. MPT-7B’s availability on the MosaicML platform facilitates the customization of language models, further promoting innovation and unlocking new opportunities for organizations across various sectors.