
TL;DR:
- Language models can achieve excellent performance by aligning them with a minimal number of training instances.
- Researchers curate a collection of 1,000 instances resembling authentic user cues and produce high-quality responses.
- LIMA, a 65-billion-parameter language model trained on this dataset, outperforms RLHF-trained models in human preference evaluations.
- LIMA’s responses are on par or better than other models in a significant number of situations.
- The study highlights the effectiveness of pretraining and the relative value of reinforcement learning and large-scale instruction tailoring.
- LIMA demonstrates the ability to engage in coherent multi-turn discourse despite lacking specific dialogue examples.
Main AI News:
Language models have undergone significant advancements in recent years, with a focus on developing transferable representations that excel in various language interpretation and generation tasks. To facilitate this transfer, researchers have proposed different approaches to aligning language models, placing particular emphasis on instruction tuning using sizable datasets and reinforcement learning from human feedback (RLHF). However, these approaches often require substantial computing power, specialized data resources, and training on millions of examples to achieve the levels of performance seen in models like ChatGPT.
A recent study challenges this prevailing notion by demonstrating that excellent performance can be achieved with just a minimal number of training instances. The researchers hypothesize that aligning a language model may be a simple and efficient process, where the model learns to adapt its format and style to engage users while leveraging the skills and knowledge acquired during pretraining. To test this hypothesis, they carefully curate a collection of 1,000 instances that resemble authentic user cues and produce high-quality responses.
The collection process involves selecting 750 of the best questions and responses from popular online discussion boards such as Stack Exchange and wikiHow, ensuring a diverse range of topics and high-quality content. Additionally, the researchers manually compose 250 instances of questions and answers, focusing on maintaining a consistent response style akin to that of an AI assistant while optimizing for task diversity.
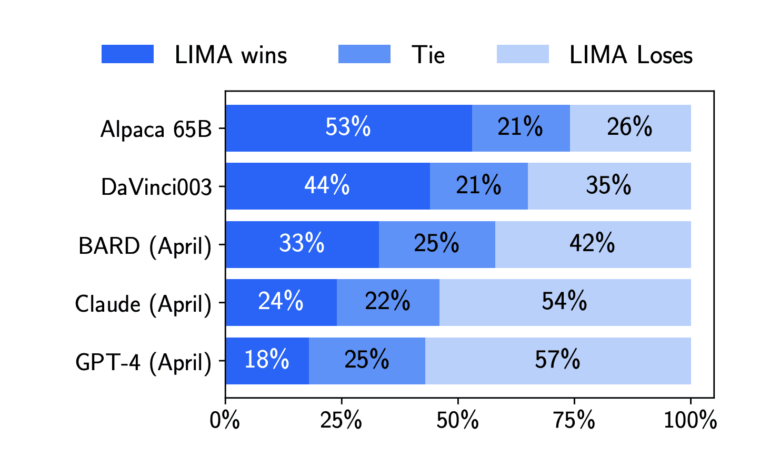
The resulting dataset is used to train LIMA, a language model with a staggering 65 billion parameters, which has already been pretrained and improved on a vast corpus of text. To evaluate LIMA’s performance, the researchers pose 300 challenging test questions, comparing its responses against those of other contemporary language models and products. The results showcase LIMA’s superiority over RLHF-trained DaVinci003 from OpenAI, as well as a 65 billion-parameter replica of Alpaca trained on 52,000 samples, based on human preferences.
While there is a general preference for GPT-4, Claude, and Bard responses over LIMA’s replies, LIMA consistently outperforms or matches the other models in 43%, 46%, and 58% of situations, respectively. To validate these findings, the researchers repeat the human preference annotations using GPT-4 as the annotator. Moreover, when evaluated on an absolute scale, 88% of LIMA’s replies meet the requirements of the given prompt, with 50% rated as outstanding.
To further investigate LIMA’s performance, ablation tests are conducted to assess the impact of data quality and prompt variety. The results indicate significant improvements when enhancing data quality, while increasing the amount of data without a corresponding increase in prompt variety leads to diminishing returns.
Interestingly, the researchers discover that LIMA demonstrates the ability to engage in coherent multi-turn discourse, even though it has not been explicitly trained on dialogue examples. This capability can be further enhanced by incorporating 30 hand-crafted dialogue chains during training.
Overall, these remarkable findings highlight the effectiveness of pretraining in developing a robust language model that can achieve outstanding performance across various prompts using just 1,000 carefully selected training instances. However, it is important to acknowledge certain limitations. Firstly, the creation of such instances requires substantial mental effort, making it challenging to scale up the process. Secondly, while LIMA generally delivers strong responses, it can sometimes generate weak outputs due to decoding issues or aggressive prompts. Therefore, it is crucial to exercise caution when utilizing LIMA in real-world applications.
Nevertheless, this work demonstrates that the alignment problem in language models can be effectively addressed, offering a promising avenue for further research and development in the field.
Conclusion:
The research showcases the potential of language models when aligned with a well-curated dataset. By training LIMA on just 1,000 carefully selected instances, the study demonstrates outstanding performance in comparison to RLHF-trained models. This finding has significant implications for the market, indicating that rather than relying solely on large-scale resources, a more efficient approach can be achieved by leveraging a smaller yet thoughtfully chosen dataset. This not only reduces the computational and data requirements but also opens up new possibilities for developing highly competitive language models that excel across various prompts and user interactions.