
TL;DR:
- Apple researchers introduce ByteFormer, an AI model that eliminates the need for explicit input modality modeling.
- ByteFormer performs inference directly on file bytes, eliminating the requirement for modality-specific preprocessing.
- The model demonstrates exceptional accuracy on various picture and audio file encodings without architectural modifications.
- ByteFormer ensures user privacy by handling inputs that maintain anonymity and can be used for partially generated images.
- Researchers provide code on GitHub, contributing to the advancement of AI modeling techniques.
Main AI News:
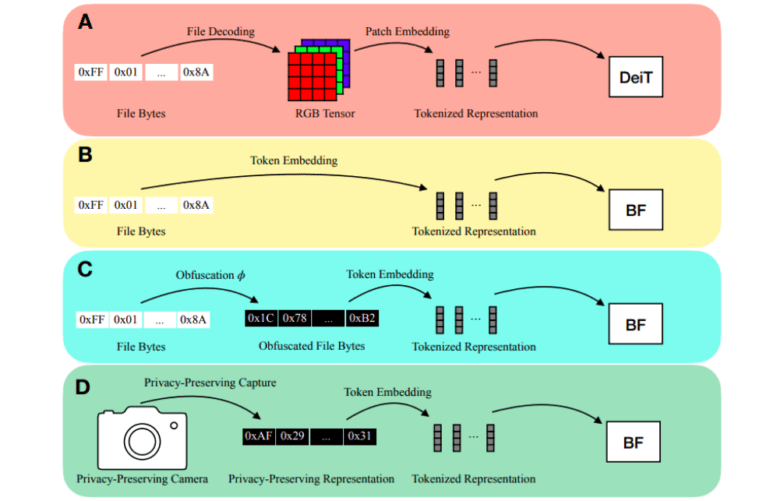
In the realm of deep learning inference, the explicit modeling of input modality has always been a prerequisite. Traditionally, techniques like encoding picture patches into vectors have enabled Vision Transformers (ViTs) to directly capture the 2D spatial organization of images. Similarly, audio inference often involves calculating spectral characteristics, such as MFCCs, to transmit into a network. Users have had to decode files into modality-specific representations, like RGB tensors or MFCCs, before making inferences on files stored on discs, be it JPEG image files or MP3 audio files (refer to Figure 1a). However, there are significant downsides to this decoding process.
The first downside is the manual creation of input representations and model stems for each input modality. Recent projects like PerceiverIO and UnifiedIO have showcased the versatility of Transformer backbones. Nonetheless, these techniques still require modality-specific input preprocessing. For instance, PerceiverIO decodes picture files into tensors before feeding them into the network, while other input modalities undergo various transformations. Apple researchers propose that by performing inference directly on file bytes, it becomes feasible to eliminate all modality-specific input preprocessing. This streamlined approach has the potential to revolutionize the field.
The second downside pertains to the exposure of analyzed material when decoding inputs into a modality-specific representation. Imagine a smart home gadget that uses RGB photos for inference. If an adversary gains access to the model input, the user’s privacy could be compromised. Apple researchers argue that inference can be conducted on inputs that protect privacy. They highlight the fact that numerous input modalities can be saved as file bytes, offering a solution to these shortcomings. Hence, they feed file bytes into their model during inference (Figure 1b) without any decoding. Leveraging a modified Transformer architecture, which excels at handling various modalities and variable-length inputs, they present ByteFormer as their model of choice.
ByteFormer, developed by researchers at Apple, demonstrates its effectiveness on ImageNet categorization using data stored in the TIFF format, achieving an impressive accuracy rate of 77.33%. By employing the DeiT-Ti transformer backbone hyperparameters, which had previously achieved 72.2% accuracy on RGB inputs, ByteFormer showcases excellent results with JPEG and PNG files as well. Remarkably, without any architectural modifications or hyperparameter tweaking, ByteFormer achieves a staggering 95.8% accuracy on Speech Commands v2, rivaling state-of-the-art performance (98.7%).
Furthermore, ByteFormer’s versatility allows it to handle inputs that prioritize privacy. The researchers show that ByteFormer can disguise inputs without sacrificing accuracy by remapping input byte values using the permutation function ϕ: [0, 255] → [0, 255] (Figure 1c). Although this approach doesn’t guarantee cryptography-level security, it serves as a foundation for masking inputs in a learning system. By employing ByteFormer to make inferences on partially generated images, greater privacy can be achieved (Figure 1d). The researchers demonstrate that ByteFormer can be trained on images with 90% of the pixels obscured and still achieve an accuracy of 71.35% on ImageNet.
An intriguing aspect of ByteFormer is that it doesn’t require precise knowledge of the unmasked pixel locations. By avoiding the typical image capture process, the representation provided to the model ensures anonymity. To summarize their contributions, the Apple researchers have created ByteFormer as a groundbreaking model for making inferences on file bytes. They showcase ByteFormer’s exceptional performance on various picture and audio file encodings without the need for architectural modifications or hyperparameter optimization. Additionally, they provide an illustrative example of how ByteFormer can be used with inputs that prioritize privacy. Their investigation explores the characteristics of ByteFormers trained to categorize audio and visual data directly from file bytes. Lastly, they have made their code available on GitHub, further contributing to the scientific community’s progress.
Conclusion:
The introduction of ByteFormer by Apple researchers represents a significant milestone in the field of AI modeling. By eliminating the need for explicit input modality modeling and preprocessing, ByteFormer streamlines the inference process, improves privacy protection, and achieves remarkable accuracy on diverse file encodings. This development has the potential to reshape the market by enabling more efficient and secure AI applications, with implications for various industries, including image and audio analysis, privacy-sensitive systems, and data security. As ByteFormer becomes more widely adopted, it is expected to drive innovation and open new possibilities in the AI market.