
TL;DR:
- Federated learning is an innovative approach to revolutionizing AI systems training.
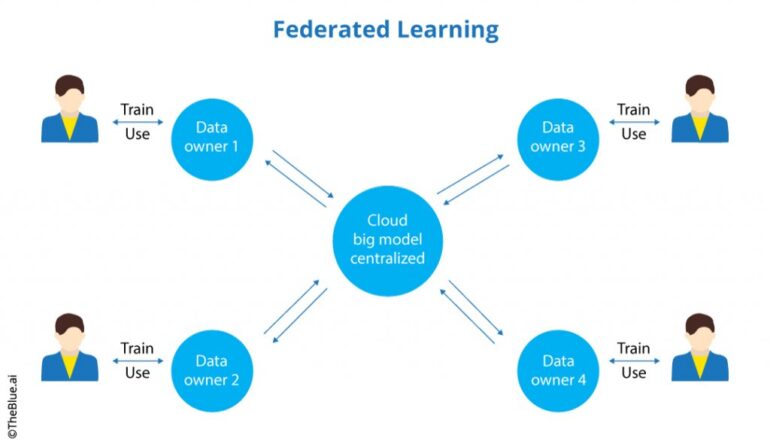
- It allows for training AI models using data from decentralized sources, without the need for centralized data storage.
- Edge devices such as smartphones, sensors, and wearables play a crucial role in federated learning by sharing data while preserving privacy.
- Federated learning offers benefits such as reduced communication and power requirements, immediate utilization, and increased privacy protection.
- Challenges include potential hacking vulnerabilities and the need for privacy-preserving strategies.
- Strategies like querying techniques and private convex optimization enhance privacy and protect against model stealing attacks.
- The cross-device dilemma necessitates personalized models for individual users, which can be achieved through clustering approaches.
- Companies should invest in privacy-preserving technologies to remain competitive and seize business opportunities.
Main AI News:
Federated learning, a groundbreaking approach in the realm of Artificial Intelligence (AI) systems training, is gaining significant attention as a transformative force. Jiaming Xu, an esteemed associate professor at Duke’s Fuqua School of Business, heralds the emergence of this novel concept and emphasizes its far-reaching implications.
To comprehend the essence of federated learning, Xu invites us to envision an octopus with nine brains. While the central brain occupies the head, each tentacle possesses a mini-brain at its base. This distributed intelligence empowers the cephalopod, as individual arms make independent decisions while exchanging information with the main brain. Through this intricate interplay, each limb enhances its efficiency, even without the central brain fully comprehending its every action.
“Federated learning is a very new concept, and the theories that undergird it are definitely going to be very important down the road,” Xu asserts confidently.
In contrast to traditional machine learning, which necessitates centralized data storage, federated learning, also known as collaborative learning, leverages input from decentralized sources to train a central model. This paradigm shift embraces the vital role played by edge devices—smartphones, climate sensors, semi-autonomous cars, satellites, bank fraud detection systems, and medical wearables. These instruments, without compromising privacy, remotely share data to perpetually refine the central learning model.
The allure of federated learning lies in the fact that data never actually leaves the edge devices—an immensely appealing feature, especially for privacy-sensitive industries like healthcare governed by regulations such as HIPAA (Health Insurance Portability and Accountability Act). Furthermore, federated learning presents additional advantages, such as reduced communication and power requirements, opportune utilization during idle device periods, and seamless applicability.
However, Xu concedes that federated learning is not a panacea. While communication between the server and edge devices remains susceptible to hacking, there exists a potential for eavesdroppers to deduce private data based on transmitted parameters. To mitigate these concerns, Xu and his colleagues, including Kuang Xu from the Stanford Graduate School of Business and Dana Yang from Cornell, have developed querying strategies and analytical techniques. These innovations contribute to the creation of theft-proof frameworks for federated learning, enhancing privacy and safeguarding against unauthorized intrusions.
“Federated learning is currently a subject of intense research,” Xu notes. “While businesses are actively exploring its potential, numerous obstacles must be overcome before these systems can be practically implemented.“
The Challenge of Thwarting Nefarious Eavesdroppers
It is worth noting that federated learning is not an entirely new concept, as companies had previously divided computation loads across computer servers to expedite AI training. Federated learning, however, takes this approach to an unprecedented level. The process involves local copies of an application residing on edge devices, with each device independently accumulating experiences and training itself. Upon receiving queries from the central server, the devices transmit their training results, excluding raw data. The server then aggregates and updates itself, offering users the opportunity to download a newer, smarter version customized with their individual data. This iterative cycle ensures that sensitive information, like emails, photos, and financial and health data, remains secure at the locations where it originated.
In his research on Optimal Query Complexity, Xu and his collaborators delve into the critical issue of preventing third parties from intercepting responses provided by edge devices. Their strategy entails querying at the fastest possible pace while safeguarding information from adversaries. This approach hinders adversaries from accurately determining the value of the information contained in the responses.
Xu presents a metaphorical analogy, likening the process to an oil company that drills numerous wells, discovers oil in only one, and seeks to prevent competitors from identifying the successful well. By sinking multiple wells simultaneously, with only one yielding actual results while the others generate fake proxies, the true source of information remains elusive to eavesdroppers.
The application of private convex optimization, as outlined in Learner-Private Convex Optimization, also plays a crucial role in obfuscating learners’ queries. By constructing multiple intervals that appear equally plausible to eavesdroppers, with only one containing the optimal choice, the true answer remains indistinguishable from numerous decoys. The adoption of mathematical methodologies such as convex optimization offers a framework to resolve conflicting requirements and achieve optimal outcomes, facilitating privacy protection in federated learning.
This same privacy-preserving objective extends to the domain of autonomous driving. Xu highlights the need to shield the privacy of a flagship manufacturer’s model from model stealing attacks by rival companies. By ensuring the stolen model performs reliably under all circumstances, the manufacturer can maintain a competitive advantage. These privacy-enhancing strategies serve as potent weapons against adversaries, rendering them powerless in the face of stolen models.
The Cross-Device Dilemma
Federated learning encompasses two distinct categories—cross-device and cross-silo. Cross-device learning, commonly associated with consumer devices, involves millions of users, whereas cross-silo learning entails a smaller number of participants, such as financial institutions or pharmaceutical companies, each possessing vast amounts of data.
While a standard model may thrive in cross-silo settings, implementing it across millions of smartphones owned by users with diverse habits presents significant challenges. Xu cites the example of Gboard, an Android keyboard that employs federated learning to predict users’ next words accurately. However, personalization poses a stumbling block.
“Your habit of typing a particular word may be different from the way I do it. If you just train a common model for everyone, it probably won’t work for everyone,” Xu explains. “The model should be predictable for all individual users.“
To address this issue, Xu and his colleagues propose a clustering-based approach to divide users into appropriate training groups. By identifying characteristics that distinguish users, such as driving conditions for autonomous vehicles, clustering enables the creation of separate models tailored to each group. Despite initial uncertainty regarding user grouping, their algorithmic approach estimates the appropriate groups and trains federated learning models accordingly.
Xu underscores the urgency for companies to prioritize privacy-preserving technologies to remain competitive in the evolving landscape. Failure to invest in these cutting-edge solutions may result in customers gravitating toward more privacy-conscious competitors. As privacy regulations continue to evolve, relying solely on internal privacy technology may restrict businesses’ access to data necessary for internal machine learning, thereby jeopardizing numerous business opportunities.
Conclusion:
The emergence of federated learning presents a transformative opportunity for the AI market. By leveraging decentralized data sources, preserving privacy, and optimizing communication, businesses can enhance their AI training capabilities. However, addressing privacy concerns and ensuring personalized models for diverse user groups will be crucial for success in this evolving landscape. Companies that prioritize privacy-preserving technologies will be better positioned to attract customers and capitalize on future AI advancements.