
- Large Language Models (LLMs) face challenges due to limited data for validation and assessing text generation quality independently.
- Cohere’s research proposes using a Panel of LLM assessors (PoLL) instead of relying solely on one large model like GPT-4 for evaluation.
- PoLL reduces intra-model bias and is more cost-effective compared to single large model evaluations.
- PoLL outperforms single large model evaluations in terms of precision and cost-efficiency, highlighting the potential of collaborative assessments from multiple smaller models.
Main AI News:
In contemporary times, the progression of Large Language Models (LLMs) is relentless. However, the scarcity of comprehensive data to validate specific attributes of these models remains a significant hurdle. An added layer of complexity emerges when appraising the accuracy and caliber of a model’s spontaneous text generation independently.
To confront these challenges, many assessments now employ LLMs as arbiters to rate the quality of outputs generated by other LLMs. This methodology frequently relies on a singular expansive model for assessment, such as the GPT-4. While this approach has gained traction, it also harbors drawbacks, including exorbitant costs, the potential for intra-model bias, and the recognition that excessively large models may be unnecessary.
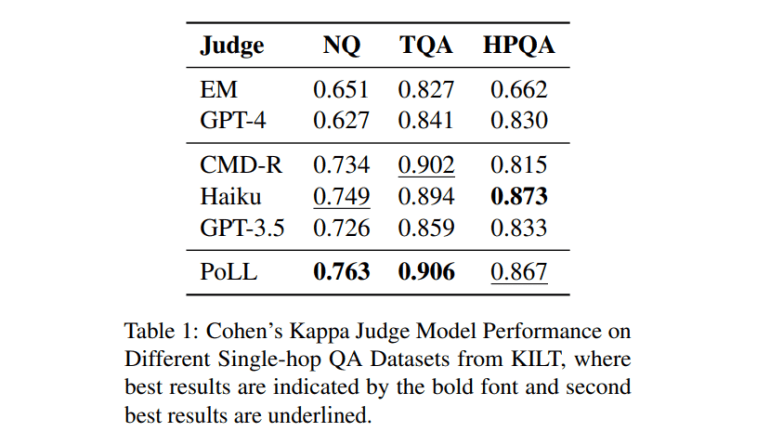
An alternative approach has emerged to tackle these issues, namely model assessment through a Panel of LLM assessors (PoLL). Instead of relying solely on one mammoth model, this concept leverages multiple smaller LLMs as assessors. The PoLL framework comprises an array of diminutive LLMs that collaborate to evaluate overall output quality.
To illustrate the efficacy of PoLL, six distinct datasets and three different assessment scenarios have been utilized. The findings demonstrate that employing a PoLL, consisting of several smaller LLMs, outperforms dependence on a single large assessor. This superiority is attributed to the following factors:
- Reduced Intra-Model Bias: By aggregating numerous smaller models from diverse model lineages into a PoLL, the bias stemming from depending solely on a solitary large model is diminished.
- Cost-Efficiency: Employing a PoLL presents a cost-saving advantage of over sevenfold compared to reliance on a solitary large LLM for evaluation.
This innovative evaluation framework employs a panel of LLM assessors to address practical biases and financial concerns while simultaneously enhancing performance. This methodology underscores the potential of collaborative assessments from a heterogeneous ensemble of smaller models to yield more precise and economical evaluations of LLMs.
The researchers have employed six diverse datasets to conduct tests across three distinct scenarios: single-hop question answering (QA), multi-hop QA, and Chatbot Arena.
The team has outlined their primary contributions as follows:
- Introduction of the PoLL Framework: Proposing a novel approach to evaluate Large Language Models, the PoLL framework eschews dependence on a single large assessor in favor of a Panel of LLM assessors drawn from various model lineages.
- Cost-Effectiveness and Correlation with Human Evaluations: The findings indicate that utilizing PoLL is significantly more cost-effective and aligns more closely with human evaluations compared to reliance on a single large assessor like GPT-4.
- Identification of Deviations in GPT-4: The study highlights instances where GPT-4 deviates markedly from the norm in terms of ratings, even with slight variations in prompts.
- Mitigation of Intra-Model Scoring Biases: The PoLL approach effectively mitigates intra-model scoring biases by amalgamating assessments from a diverse panel of evaluator models.
Conclusion:
Cohere’s research on leveraging a Panel of LLM Assessors (PoLL) for model evaluation suggests a more effective and economical approach compared to depending solely on single large models. This indicates a shift towards collaborative evaluation methods in the market, emphasizing the importance of precision and cost-efficiency in assessing Large Language Models.