
TL;DR:
- MIT researchers explore how language models like LLMs comprehend visual information.
- The study evaluates LLMs’ capabilities in representing the visual world.
- LLMs’ potential for generating and recognizing visual concepts is examined.
- The innovative approach uses textual descriptions to generate visual representations.
- Comprehensive methodology tests LLMs’ image generation and recognition abilities.
- LLMs excel in generating complex scenes but struggle with intricate details.
- Iterative text-based feedback enhances LLMs’ visual generation capabilities.
Main AI News:
In a groundbreaking study, MIT researchers delve into the fascinating intersection of language models and visual perception, exploring how text-based models like LLMs (Language Models) interpret and embody visual information. This groundbreaking research venture navigates uncharted waters, probing the extent to which models primarily designed for text processing can encapsulate and represent visual concepts—a formidable challenge given the inherently non-visual nature of these language models.
The central question addressed by this research is the evaluation of LLMs’ capabilities. These models, predominantly trained on textual data, are put to the test in their comprehension and representation of the visual realm. Until now, language models have been strangers to visual data in its image form. This study aspires to unravel the boundaries and competencies of LLMs in the realms of generating and recognizing visual concepts, illuminating the uncharted territory of textual models navigating the domain of visual perception.
[Free AI Event] ‘Meet SingleStore Pro Max, the Powerhouse Edition’ (Jan 24, 2024, 10 am PST)
The Current Perception of LLMs: Textual Titans or Visual Visionaries?
Historically, LLMs like GPT-4 have been hailed as powerhouses of text generation. However, the realm of visual concept generation within these models remains a captivating enigma. Earlier studies have offered tantalizing hints of LLMs’ potential to grasp perceptual concepts, such as shapes and colors, and embed these aspects within their internal representations. These internal representations, intriguingly, align to some extent with those cultivated by dedicated vision models, hinting at a latent potential for visual understanding residing within text-based models.
MIT CSAIL Researchers Pave the Way for Visual Assessment
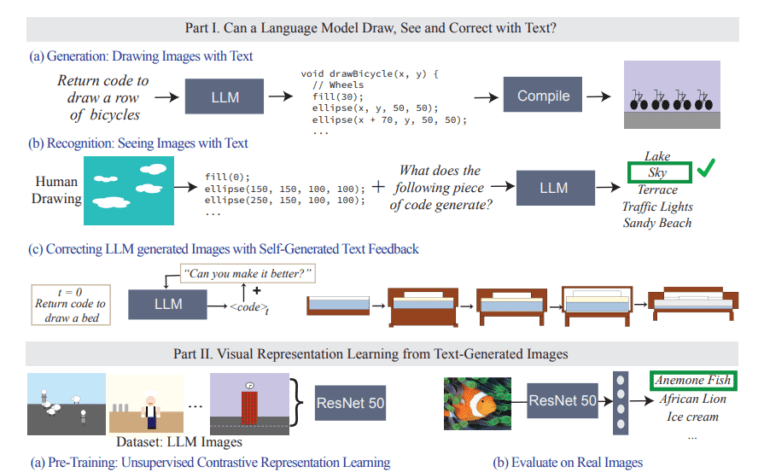
MIT CSAIL researchers have introduced an innovative approach to assess the visual prowess of LLMs. They have devised a method in which LLMs are assigned the task of generating code that visually renders images based on textual descriptions of various visual concepts. This groundbreaking technique adeptly sidesteps the limitations of LLMs in directly crafting pixel-based images. Instead, it harnesses its textual processing prowess to embark on the fascinating journey of visual representation.
A Multifaceted Methodology Unveiled
The methodology employed in this study is nothing short of comprehensive and multifaceted. LLMs are prompted to create executable code from textual descriptions that encompass a diverse array of visual concepts. The generated code then serves as the blueprint for rendering images that vividly portray these concepts, effectively translating the text into captivating visual representations. Researchers rigorously scrutinize LLMs across a spectrum of complexities, from basic shapes to intricate scenes, meticulously evaluating their image generation and recognition capabilities. This rigorous evaluation spans various visual dimensions, including the complexity of the scenes, the accuracy of concept depiction, and the models’ adeptness in recognizing these visually portrayed representations.
Intriguing Insights into LLMs’ Visual Proficiency
The study’s findings unveil intriguing insights into LLMs’ visual understanding capabilities. These textual titans showcase a remarkable aptitude for generating intricate and detailed graphic scenes, a testament to their versatility. However, a note of caution arises as their performance exhibits non-uniformity across various tasks. While they excel in constructing complex scenes, LLMs grapple with capturing intricate details such as textures and precise shapes. An illuminating facet of the study lies in the utilization of iterative text-based feedback, a process that significantly enhances the models’ prowess in visual generation. This iterative journey points to an adaptive learning capability residing within LLMs, where they continuously refine and enhance their visual representations based on continuous textual input.
Conclusion:
MIT’s research highlights the evolving potential of language models in the realm of visual understanding. While LLMs show promise in generating complex visual scenes, their limitations with finer details suggest opportunities for specialized visual models. Businesses should monitor these developments as they may impact applications requiring text-based models in visual contexts.