
TL;DR:
- Recent research introduces AttrPrompt, a groundbreaking approach for zero-shot learning.
- Large language models (LLMs) have been utilized as data generators to reduce the need for task-specific data and annotations.
- The study analyzes four challenging subject classification tasks across different domains and evaluates the level of bias and diversity in the training set.
- The researchers employ ChatGPT as the anchor LLM, leveraging its ability to produce high-quality human-like language.
- By generating data with diverse attribute prompts, the researchers reduce attribute biases and enhance attribute diversity in the generated dataset.
- Empirical evaluations demonstrate that AttrPrompt outperforms SimPrompt in terms of data efficiency, flexibility, and overall performance in multi-label classification problems.
- AttrPrompt requires only 5% of the querying cost associated with ChatGPT used in SimPrompt.
- This revolutionary breakthrough in zero-shot learning has significant implications for the AI market.
Main AI News:
Large language models (LLMs) have undeniably demonstrated remarkable performance across numerous natural language processing (NLP) applications. Recent studies have harnessed the power of LLMs as task-specific training data generators, minimizing the need for specialized data and annotations, particularly in text classification. While these endeavors have showcased the efficacy of LLMs in data production, they have primarily focused on enhancing the training phase, neglecting the crucial upstream data creation process. However, a groundbreaking AI research initiative is set to revolutionize this paradigm.
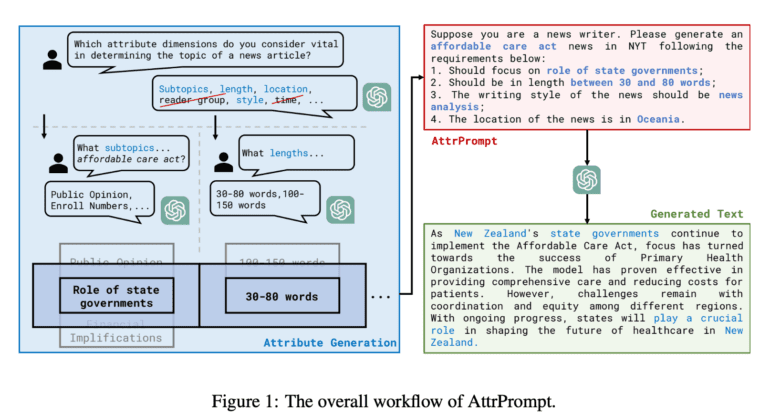
A collaborative study conducted by esteemed institutions such as Georgia Tech, University of Washington, UIUC, and Google Research has meticulously examined four challenging subject classification tasks encompassing a wide range of domains. In this study, the researchers harnessed the prowess of ChatGPT as the anchor LLM, renowned for its ability to generate human-like, high-quality language. To gauge the level of bias and diversity within the constructed training set, the team predominantly employed data attributes as evaluation metrics. These data attributes encompassed diverse attribute dimensions and various attribute values, each representing a plausible manifestation of the respective attributes.
Employing a trained attribute classifier, the researchers closely scrutinized the attribute bias within the dataset generated by SimPrompt. Their objective was to unravel the impact of different attributes on the final results of a model. By utilizing ChatGPT, they generated attributed data while incorporating constraints on the questions to embody specific attribute values. Intriguingly, the findings indicated that models trained on datasets characterized by random attributes outperformed those trained on datasets with fixed attributes, thus underscoring the pivotal role of attribute variation in the generated dataset.
To mitigate attribute biases and bolster attribute diversity in the generated data, the research team proposes a novel approach: diversely attributed prompts. Leveraging the capabilities of the LLM, they devised an interactive, semi-automated process that determines the appropriate attribute dimensions and values for a given classification task. The traditional class-conditional prompt used for LLM data inquiries is then replaced with more intricate queries generated by randomly combining various properties. This novel technique has been aptly named “AttrPrompt,” encapsulating the multitude of attributable triggers it encompasses.
The researchers conducted empirical evaluations on the four classification tasks by comparing the performance of models trained under two scenarios: 1) solely on the generated dataset and 2) on a merged dataset that incorporates the genuine training set along with the generated set. Remarkably, the dataset created using AttrPrompt outshone the dataset generated by SimPrompt in both cases. Furthermore, the results highlighted that AttrPrompt surpasses SimPrompt in terms of data/budget efficiency and flexibility across a broad spectrum of model sizes and LLM-as-training-data-generator strategies.
An exceptional attribute of AttrPrompt lies in its ability to deliver performance comparable to SimPrompt while requiring a mere 5% of the querying cost associated with ChatGPT. This unparalleled efficiency sets AttrPrompt apart. To top it off, the researchers achieved an unprecedented milestone, showcasing that AttrPrompt outperforms SimPrompt across all evaluation criteria, successfully extending the LLM-as-training-data-generator paradigm to the intricate realm of multi-label classification problems.
Conclusion:
The introduction of AttrPrompt represents a significant advancement in zero-shot learning. Addressing attribute biases and increasing data diversity, it provides enhanced performance, reduced costs, and improved flexibility for AI applications. This breakthrough has the potential to reshape the AI market, offering new opportunities and efficiencies for businesses across various industries.