
- Multimodal Large Language Models (MLLMs) blend language processing and computer vision.
- Hallucination, where MLLMs generate inaccurate responses, is a pressing issue.
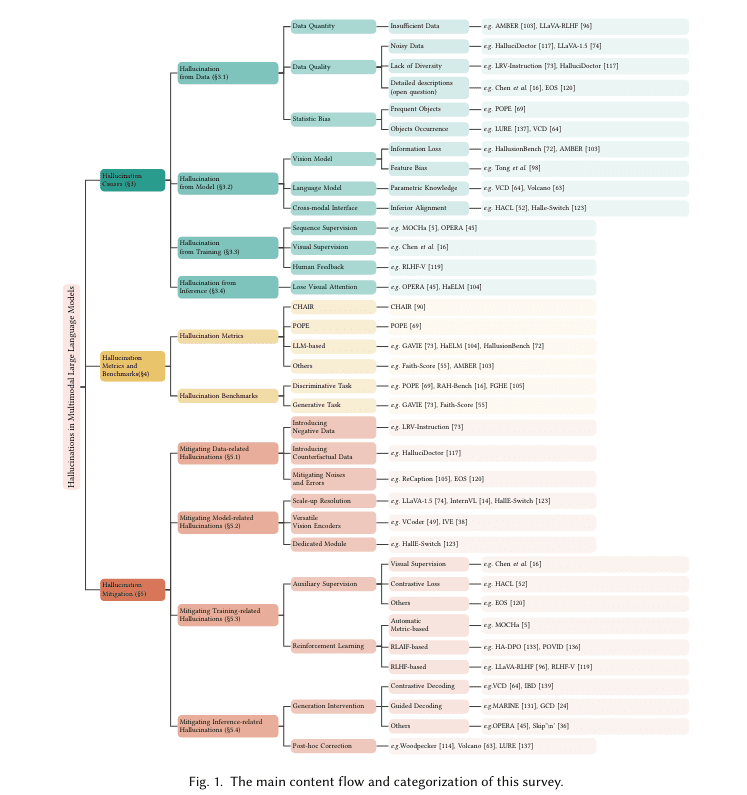
- Traditional efforts involve refining models through extensive training with annotated datasets.
- Collaborative research proposes novel alignment techniques and data quality assessment to reduce hallucinations.
- Results show a 30% reduction in hallucination incidents and a 25% improvement in answering visual questions.
Main AI News:
In the realm of artificial intelligence, Multimodal Large Language Models (MLLMs) stand at the forefront, blending the realms of language processing and computer vision to comprehend and generate responses encompassing both textual and visual elements. Unlike their predecessors, which focused solely on either text or images, these advanced models are equipped to tackle complex tasks necessitating a unified approach, from describing images to aiding visually impaired individuals in navigating their surroundings.
However, a significant challenge facing these cutting-edge models is the issue of ‘hallucination.’ This phenomenon occurs when MLLMs produce responses that appear plausible but lack factual accuracy or fail to align with the visual content they are analyzing. Such inaccuracies not only erode trust in AI systems but also pose serious implications in critical domains like medical imaging and surveillance, where precision is non-negotiable.
Traditional efforts to mitigate these inaccuracies have centered on refining the models through rigorous training regimes leveraging extensive datasets of annotated images and text. Despite these endeavors, the problem persists, primarily due to the inherent complexities involved in teaching machines to accurately interpret and correlate multimodal data. Instances include models describing non-existent elements in images, misinterpreting actions within scenes, or overlooking contextual cues in visual inputs.
A collaborative research effort led by scholars from the National University of Singapore, Amazon Prime Video, and AWS Shanghai AI Lab has delved into innovative methodologies aimed at curtailing hallucinations. One such approach involves refining the standard training paradigm by integrating novel alignment techniques, bolstering the model’s capacity to associate specific visual cues with precise textual descriptions. Additionally, this method entails a meticulous assessment of data quality, prioritizing diversity and representativeness within training sets to mitigate common biases leading to hallucinations.
The quantitative enhancements observed across various performance metrics serve as a testament to the effectiveness of these refined models. Benchmark assessments focusing on image caption generation have revealed a notable 30% reduction in hallucination incidents compared to earlier iterations. Moreover, the models have exhibited a 25% enhancement in accurately responding to visual queries, indicative of a more profound comprehension of the visual-textual interface.
Source: Marktechpost Media Inc.
Conclusion:
The advancement of strategies to mitigate hallucination in Multimodal Large Language Models signifies a significant leap forward in enhancing the reliability and accuracy of AI systems. Businesses utilizing such models, especially in critical sectors like medical imaging and surveillance, can expect improved performance, bolstering trust and confidence in AI-driven solutions. This progress underscores the importance of ongoing research and innovation in refining AI technologies to meet the demands of diverse industries.