
- Aaren introduces a novel approach by reinterpreting attention mechanism as a form of recurrent neural network (RNN), optimizing resource utilization in sequence modeling.
- Unlike traditional RNNs, Aaren leverages parallel prefix scan algorithm to compute attention outputs efficiently, handling sequential data with constant memory requirements.
- Empirical validations across various tasks demonstrate Aaren’s efficiency and robustness, showcasing competitive performance with Transformers in reinforcement learning, event forecasting, and time series analysis.
- Aaren exhibits promising results across real-world datasets, achieving comparable performance to Transformers while reducing computational overhead.
- The innovative methodology of Aaren holds significant implications for resource-constrained environments and diverse applications requiring efficient sequence modeling.
Main AI News:
The landscape of machine learning is continuously evolving, with sequence modeling emerging as a pivotal domain powering diverse applications such as reinforcement learning, time series forecasting, and event prediction. Within this domain, the order of input data holds paramount significance, particularly in fields like robotics, financial forecasting, and medical diagnoses. Historically, Recurrent Neural Networks (RNNs) have served as the backbone for sequence modeling, excelling in processing sequential data efficiently despite inherent limitations in parallel processing capabilities.
However, the rapid advancement in machine learning has accentuated the inadequacies of existing models, especially in resource-constrained environments. While Transformers have gained prominence for their unparalleled performance and ability to harness GPU parallelism, their resource-intensive nature renders them impractical for deployment in low-resource settings such as mobile and embedded devices. The primary obstacle lies in their quadratic memory and computational demands, which pose significant challenges in scenarios with limited computational resources.
Various attempts have been made to address these challenges, including the development of attention-based models and methods. Despite their superior performance, Transformers remain resource-intensive. Approximations like RWKV, RetNet, and Linear Transformer offer linearizations of Attention to enhance efficiency but are plagued by limitations in token bias. Alternatively, attention computation can be approached recurrently, as demonstrated by Rabe and Staats, while softmax-based Attention can be reformulated as an RNN. Additionally, efficient algorithms for computing prefix scans, pioneered by Hillis and Steele, provide foundational techniques for optimizing attention mechanisms in sequence modeling. Nevertheless, these techniques must effectively mitigate the inherent resource intensity, especially in applications dealing with lengthy sequences such as climate data analysis and economic forecasting. Consequently, there is a growing exploration of alternative methodologies that balance performance with resource efficiency.
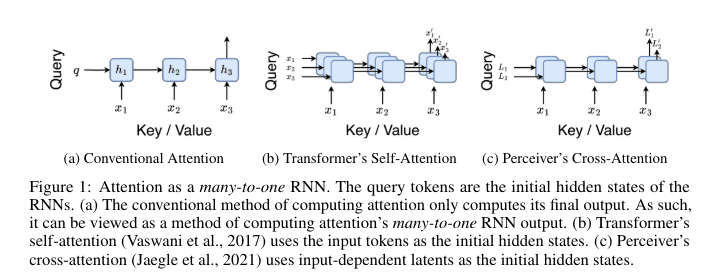
In response to these challenges, researchers from Mila and Borealis AI have introduced Attention as a Recurrent Neural Network (Aaren), a groundbreaking approach that reimagines the attention mechanism as a variant of RNN. This innovative paradigm preserves the parallel training advantages of Transformers while enabling efficient updates with new tokens. Unlike conventional RNNs, which process data sequentially and encounter scalability issues, Aaren leverages a parallel prefix scan algorithm to compute attention outputs more efficiently, thereby managing sequential data with constant memory requirements. This characteristic makes Aaren exceptionally well-suited for low-resource environments where computational efficiency is of utmost importance.
At its core, Aaren operates by conceptualizing the attention mechanism as a many-to-one RNN. While traditional attention methods compute outputs in parallel, necessitating linear memory with respect to the number of tokens, Aaren introduces a novel approach by computing Attention as a many-to-many RNN, substantially reducing memory utilization. This optimization is facilitated through a parallel prefix scan algorithm, enabling Aaren to process multiple context tokens concurrently while efficiently updating its state. The computation of attention outputs involves a series of associative operations, ensuring consistent memory and computational load irrespective of the sequence length.
Empirical evaluations have underscored the efficacy and resilience of Aaren across diverse tasks. In reinforcement learning scenarios, Aaren underwent rigorous testing on 12 datasets within the D4RL benchmark, spanning environments such as HalfCheetah, Ant, Hopper, and Walker. The results showcased Aaren’s competitive performance vis-à-vis Transformers, yielding notable scores like 42.16 ± 1.89 for Medium datasets in the HalfCheetah environment. This efficiency extends to event forecasting, where Aaren exhibited robust performance across eight popular datasets. For instance, on the Reddit dataset, Aaren achieved a negative log-likelihood (NLL) of 0.31 ± 0.30, demonstrating performance on par with Transformers but with reduced computational overhead.
Furthermore, Aaren demonstrated its mettle across eight real-world datasets in time series forecasting encompassing domains such as Weather, Exchange, Traffic, and ECL. Notably, on the Weather dataset, Aaren attained a mean squared error (MSE) of 0.24 ± 0.01 and a mean absolute error (MAE) of 0.25 ± 0.01 for a prediction length of 192, underscoring its efficacy in handling time series data proficiently. Similarly, Aaren exhibited comparable performance to Transformers across ten datasets from the UEA time series classification archive, thereby affirming its versatility and effectiveness in diverse applications.
Conclusion:
Aaren’s disruptive approach to sequence modeling, by reimagining attention as a recurrent neural network, signifies a significant leap in resource-efficient algorithms. This innovation not only addresses the limitations of existing models in resource-constrained settings but also opens doors for enhanced performance across diverse applications. Businesses operating in sectors reliant on efficient sequence modeling can leverage Aaren to optimize resource utilization and drive better outcomes in tasks such as reinforcement learning, event prediction, and time series forecasting.