
TL;DR:
- ActorsNeRF, a breakthrough in 3D human representation, was introduced by UCSD and ByteDance researchers.
- It builds upon the Neural Radiance Fields (NeRF) technique for capturing 3D scenes from 2D images.
- ActorsNeRF generalizes to unseen actors with only a few images, making it highly versatile.
- It employs a 2-level canonical space concept for realistic character movements and deformations.
- Researchers fine-tune the model to adapt to specific actor characteristics.
- ActorsNeRF outperforms the HumanNeRF approach, excelling in generating novel human actors.
- Tested across various benchmarks, it demonstrates impressive results in a few-shot setting.
Main AI News:
Researchers at the University of California, San Diego (UCSD) and ByteDance have introduced a groundbreaking innovation in the realm of 3D human representation: ActorsNeRF. This cutting-edge technology, inspired by Neural Radiance Fields (NeRF), stands as a pioneering solution for generating animatable human actors, even those unseen, in a few-shot scenario.
NeRF, a formidable neural network-based methodology, has been widely acclaimed for its capacity to reconstruct 3D environments and objects from 2D images or sparse 3D data. The NeRF system comprises two integral components: “NeRF in” and “NeRF out.” The former takes 2D pixel coordinates and camera poses as input, producing a feature vector, while the latter leverages this feature vector to predict the 3D position and color attributes of the corresponding 3D point.
To create a NeRF-based human representation, the typical approach involves capturing images or videos of a human subject from multiple vantage points. These visuals may be sourced from various devices, such as cameras, depth sensors, or 3D scanners. The applications for NeRF-based human representations span diverse domains, encompassing virtual avatars for gaming and virtual reality, 3D modeling for animation and filmmaking, and medical imaging for the creation of patient-specific 3D models used in diagnosis and treatment planning. However, it’s worth noting that this process can be computationally intensive and necessitates substantial training data.
The path to success in this endeavor entails a combination of synchronized multi-view videos and a NeRF network designed for specific human video sequences. To overcome these challenges, the researchers have proposed a novel approach known as ActorsNeRF. This innovative model operates at the category level and exhibits the remarkable ability to generalize to unseen actors within a few-shot framework. Astonishingly, with just a limited number of images—approximately 30 frames—extracted from a monocular video, ActorsNeRF can synthesize high-quality novel perspectives of previously unseen actors, all within the AIST++ dataset.
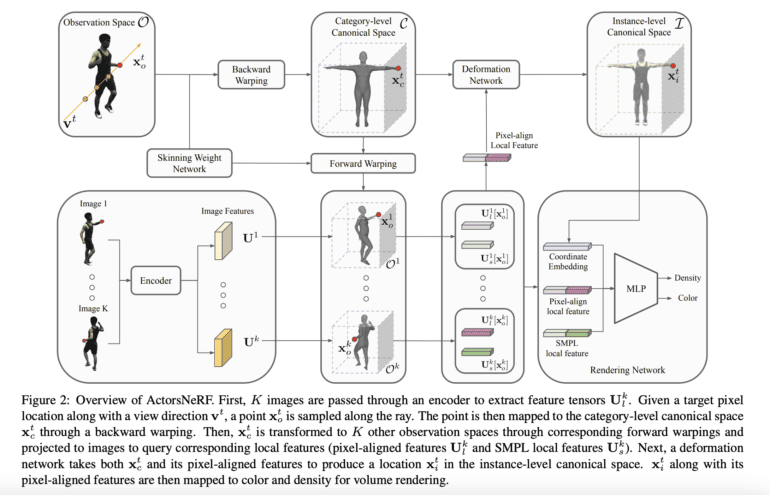
The methodology employed here follows a 2-level canonical space concept. For a given body pose and rendering viewpoint, a sampled point in 3D space undergoes an initial transformation into canonical space through linear blend skinning. These skinning weights, which govern the deformation of a 3D mesh representing a character during animation, are determined by a skinning weight network shared across different subjects. This is paramount for achieving realism in character movements and deformations within the realm of 3D computer graphics.
To achieve the much-desired generalization across diverse individuals, the researchers took a proactive approach. They trained the category-level NeRF model on a diverse assortment of subjects. During the inference phase, this pretrained model was fine-tuned with a minimal number of images depicting the target actor, enabling it to adapt to the distinctive characteristics of each actor.
The results have been nothing short of extraordinary. ActorsNeRF has consistently outperformed the HumanNeRF approach, delivering significantly more accurate representations, particularly for less observed body parts. This underscores ActorsNeRF’s capacity to effectively utilize category-level information while seamlessly synthesizing unobserved portions of the human body. Rigorously tested across various benchmarks, including ZJU-MoCap and AIST++ datasets, ActorsNeRF has established itself as a formidable performer, excelling in the generation of novel human actors with unseen poses across multiple few-shot scenarios. In the ever-evolving landscape of 3D human representation, ActorsNeRF stands as a testament to the power of innovation and the pursuit of excellence.
Conclusion:
ActorsNeRF represents a game-changing advancement in 3D human representation. Its ability to create animatable human actors from minimal data and outperform existing methods has profound implications for industries ranging from gaming and film production to medical imaging. This innovation positions UCSD and ByteDance as leaders in the evolving market of 3D content creation and virtual reality.