
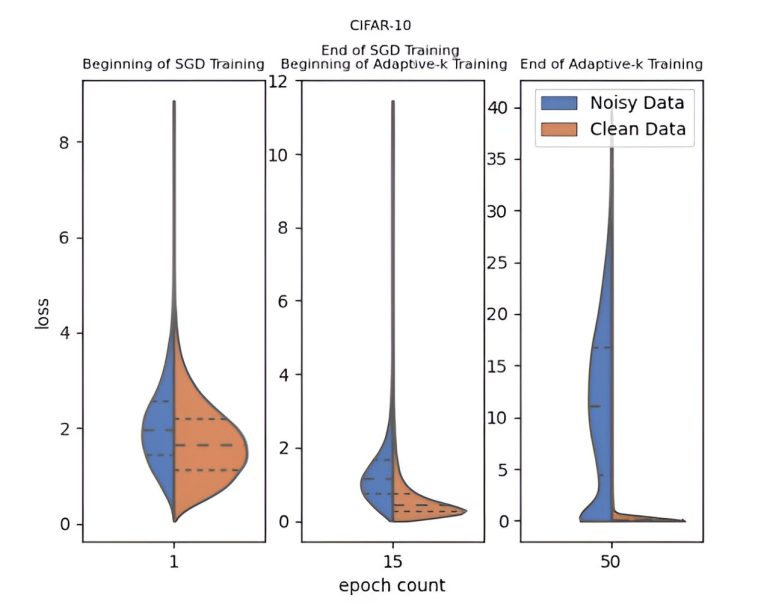
- Adaptive-k method optimizes training in datasets with label noise.
- Introduced by researchers from Yildiz Technical University.
- Adaptively selects samples from mini-batches, distinguishing clean from noisy data.
- Simple and efficient, requiring no prior noise ratio knowledge or extra training time.
- Comparable performance to the Oracle method without needing perfect noise knowledge.
- Outperforms traditional algorithms like Vanilla, MKL, and Trimloss.
- Compatible with popular optimizers such as SGD, SGDM, and Adam.
- Accurate clean sample ratio estimation demonstrated on the MNIST dataset.
- Researchers plan to refine and expand the method’s applications.
Main AI News:
In deep learning, the presence of label noise in datasets can significantly hinder model performance. To tackle this challenge, researchers from Yildiz Technical University—Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali—have introduced a novel Adaptive-k method. Recently published in Frontiers of Computer Science, this approach optimizes the training process by adaptively selecting the number of samples from each mini-batch, effectively distinguishing between clean and noisy data, and improving overall model accuracy.
Adaptive-k’s strength lies in its simplicity and efficiency. Unlike many existing methods, it does not require prior knowledge of the dataset’s noise ratio, additional model training, or extended training time. It delivers results comparable to the Oracle method, which operates under the ideal but impractical assumption of perfect knowledge of noisy samples.
The research team conducted extensive tests across multiple image and text datasets, consistently showing that Adaptive-k outperforms traditional algorithms like Vanilla, MKL, and Trimloss in noisy environments. Its compatibility with popular optimizers such as SGD, SGDM, and Adam further enhances its versatility across various deep-learning applications.
Adaptive-k also demonstrates impressive accuracy in estimating clean sample ratios during training, as evidenced by its performance on the MNIST dataset. This capability, achieved without prior dataset knowledge or hyperparameter tuning, underscores its robustness.
The researchers plan to refine Adaptive-k, explore new applications, and improve its performance. As the need for robust training methods in deep learning grows, Adaptive-k is poised to become a vital tool for building more reliable and noise-resistant models.
Conclusion:
The introduction of Adaptive-k marks a significant advancement for the deep learning market, particularly in handling noisy datasets. This method’s simplicity, efficiency, and compatibility with existing optimizers offer a competitive edge, reducing the need for extensive data cleaning and preprocessing. As companies increasingly rely on deep learning for critical decision-making, Adaptive-k presents a valuable tool for enhancing model accuracy and reliability, potentially driving further innovation and adoption in sectors reliant on data-driven insights. This development could lead to more robust AI applications, ultimately benefiting businesses by improving the quality of predictions and reducing the risks associated with noisy data.