
TL;DR:
- Adept AI’s Fuyu-8B simplifies the fusion of textual and visual data for digital agents.
- Fuyu-8B’s basic decoder-only transformer eliminates the need for a specialized image encoder.
- The model excels at comprehending complex diagrams, charts, graphs, and OCR tasks.
- Fuyu-8B performs exceptionally well in standard image understanding benchmarks.
- Its user-friendly architecture paves the way for future AI tool development.
- Fuyu-8B represents a significant step towards enhancing multimodal models for efficient image comprehension.
Main AI News:
In the realm of artificial intelligence, the fusion of textual and visual data has long posed a formidable challenge, especially when it comes to crafting highly efficient digital agents. Adept AI’s recent unveiling of Fuyu-8B represents a monumental leap forward in simplifying the understanding of multimodal images. Designed to cater to the needs of digital agents and the intricate demands of unstructured knowledge worker data, Fuyu-8B stands as a groundbreaking development in the world of cohesive text-image processing. This advancement heralds a more streamlined and intuitive approach to managing complex data integration tasks, ushering in new possibilities for efficient AI-driven solutions across diverse domains.
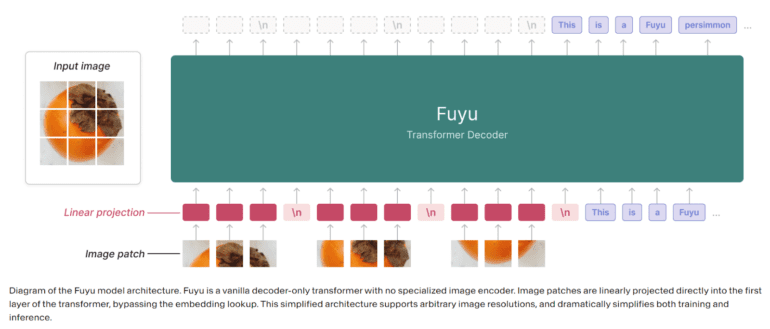
While many existing models grapple with convoluted architectures, Fuyu-8B sets itself apart by embracing simplicity and efficiency. Developed by Adept AI, this model leverages a basic decoder-only transformer, obviating the necessity for a specialized image encoder. Fuyu-8B’s adaptable framework seamlessly handles text and images, effortlessly accommodating a range of image resolutions. Its innovative design empowers Fuyu-8B to not only comprehend intricate diagrams, charts, and graphs but also execute Optical Character Recognition (OCR) tasks on screens and respond to user interface (UI)-based queries, solidifying its position as a versatile and indispensable tool in various AI applications.
The impressive performance of Fuyu-8B can be primarily attributed to its simplified architecture, which streamlines the integration of text and image data. By bypassing the complexities associated with specialized image encoders, the model offers users an intuitive and efficient workflow, enabling them to navigate the intricacies of multimodal data with ease. Its adept handling of complex diagrams, charts, and graphs, along with its proficiency in OCR tasks, underscores its adaptability and versatility in processing a myriad of image-based queries. Despite its straightforward design, Fuyu-8B has demonstrated exceptional performance in standard image understanding benchmarks, cementing its reputation as a frontrunner among multimodal AI models.
The introduction of Fuyu-8B signifies a significant stride in the ongoing quest to simplify and enhance multimodal models for efficient image comprehension. Adept AI’s focus on simplicity and functionality represents a pivotal advancement, effectively addressing the complexities associated with image processing and comprehension. Fuyu-8B’s remarkable performance and user-friendly architecture lay the groundwork for the future evolution of AI tools, highlighting the crucial importance of intuitive and adaptable models that cater to the evolving requirements of digital agents and knowledge workers. With its practicality and seamless integration capabilities, Fuyu-8B serves as a herald of the ongoing evolution of multimodal models within the realms of AI and machine learning, promising a plethora of innovative possibilities for the future.
Conclusion:
The introduction of Fuyu-8B by Adept AI signifies a substantial advancement in multimodal AI, streamlining complex data integration for digital agents. This innovation has the potential to reshape the market by offering a user-friendly solution for efficient image understanding, opening doors to a wide range of AI-driven applications across various industries.