
- MLLMs are evolving rapidly in text-image interaction through innovative techniques.
- Key models use learnable queries and projection-based interfaces to enhance performance.
- Dataset quality improves question-answering, image perception, reasoning, and OCR tasks.
- The Img-Diff dataset emphasizes image difference analysis, enhancing VQA and object localization.
- Img-Diff builds on previous methods, setting new standards in visual analysis.
- Fine-tuned models with Img-Diff outperform others in various image difference and VQA tasks.
- The development of Img-Diff involved rigorous filtering and the generation of high-quality data.
Main AI News:
Multimodal Language Models (MLLMs) are advancing rapidly in text-image interaction, driven by innovative techniques like learnable queries in models such as Flamingo, IDEFICS, BLIP-2, and Qwen-VL, and projection-based interfaces used in LLaVA and MGM. Efficiency is further enhanced by models like LLaMA-Adapter and LaVIN, which focus on parameter-efficient tuning. Dataset quality remains crucial, with refined visual instruction tuning datasets improving question-answering tasks, image perception, reasoning, and OCR.
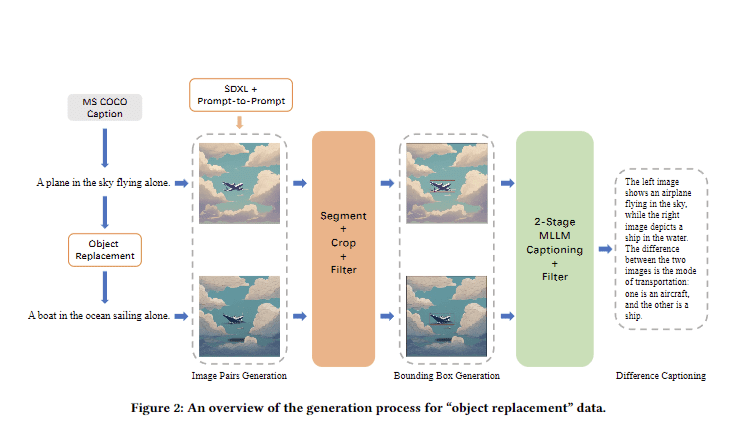
The Img-Diff dataset introduces a novel approach by emphasizing image difference analysis, significantly boosting MLLMs’ VQA and object localization capabilities. Img-Diff builds on previous work like Shikra, ASM, and PINK by focusing on fine-grained image recognition, setting a new visual analysis standard.
Designed to sharpen MLLMs’ skills in identifying subtle differences between similar images, Img-Diff employs a Difference Area Generator and Difference Captions Generator to challenge models. Fine-tuned with Img-Diff, models outperform their peers on various image difference and VQA tasks, highlighting the importance of high-quality, specialized datasets. Img-Diff’s development process, involving the creation of 118,000 image pairs filtered down to 38,533, along with the generation of 117,779 bounding box data points and 12,688 detailed “object replacement” instances, underscores its potential to elevate MLLMs’ fine-grained image recognition capabilities.
Conclusion:
The introduction of the Img-Diff dataset represents a significant leap forward in the field of multimodal language models (MLLMs). Its emphasis on fine-grained image recognition and difference analysis equips MLLMs with the capability to outperform existing models in tasks that require nuanced visual comprehension. For the market, this means a new benchmark for AI-driven visual analysis tools, which could lead to more advanced applications in sectors such as security, healthcare, and retail. The success of Img-Diff underscores the growing importance of specialized, high-quality datasets in driving the next wave of AI innovation, positioning companies that invest in these areas as potential leaders in a highly competitive market.