
- Researchers develop CausalBench, a benchmark for assessing AI models’ causal reasoning.
- Causal learning is crucial for AI operational effectiveness and decision-making.
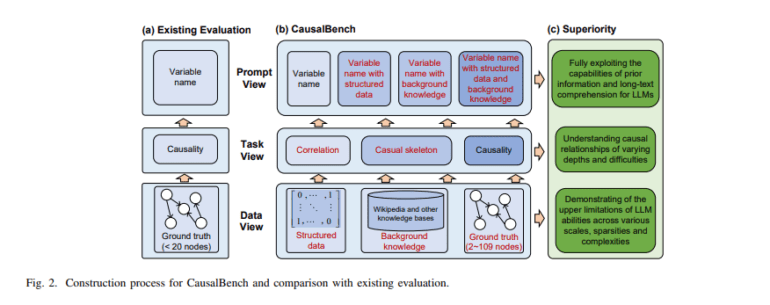
- Existing evaluations lack diversity in task complexity and dataset variety.
- CausalBench offers comprehensive evaluation through various tasks and datasets.
- Performance metrics include F1 score, accuracy, SHD, and SID.
- Preliminary results show significant performance variations among LLMs.
- Findings provide insights for improving model training and algorithm development.
Main AI News:
Exploring the depths of causal reasoning within artificial intelligence (AI) models is paramount for their operational effectiveness in real-world scenarios. Understanding causality not only influences decision-making processes but also enhances adaptability and fosters the ability to envision alternative outcomes. Despite the proliferation of large language models (LLMs), evaluating their causal reasoning capabilities remains a formidable task, necessitating a robust benchmarking framework.
Traditional approaches to evaluating LLMs often involve simplistic correlation tasks, relying on limited datasets with straightforward causal structures. While models like GPT-3 and its variants have been subject to such assessments, they lack diversity in task complexity and dataset variety. This dearth of comprehensive evaluation methodologies hampers the exploration of LLM capabilities across realistic and intricate scenarios, underscoring the need for innovation in causal learning assessment.
Addressing this gap, researchers from Hong Kong Polytechnic University and Chongqing University have introduced CausalBench, a cutting-edge benchmark designed to rigorously evaluate LLMs’ causal reasoning abilities. CausalBench sets itself apart through its holistic approach, encompassing various levels of complexity and a diverse range of tasks that challenge LLMs to interpret and apply causal reasoning in diverse contexts. By simulating real-world scenarios, this methodology ensures a thorough evaluation of model performance.
The CausalBench methodology involves assessing LLMs with datasets such as Asia, Sachs, and Survey to gauge their understanding of causality. Tasks include identifying correlations, constructing causal skeletons, and determining causality directions. Performance metrics encompass F1 score, accuracy, Structural Hamming Distance (SHD), and Structural Intervention Distance (SID), providing insights into each model’s innate causal reasoning capabilities without prior fine-tuning. This zero-shot evaluation approach reflects the fundamental aptitude of LLMs to process and analyze causal relationships across increasingly complex scenarios.
Preliminary evaluations using CausalBench unveil significant performance variations among different LLMs. While models like GPT4-Turbo demonstrate commendable F1 scores above 0.5 in correlation tasks on datasets like Asia and Sachs, their performance wanes in more intricate causality assessments involving the Survey dataset. Here, many models struggle to surpass F1 scores of 0.3, shedding light on their varying capacities to navigate diverse levels of causal complexity. These findings serve as a benchmark for success and offer valuable insights for enhancing model training and algorithmic development in the future.
Conclusion:
The introduction of CausalBench marks a significant advancement in evaluating AI models’ causal reasoning abilities. With insights from comprehensive evaluations, businesses can tailor their AI strategies to leverage the strengths and address the weaknesses of different LLMs, ultimately enhancing operational efficiency and decision-making processes in various sectors.