
- AssemblyAI introduces Universal-1, surpassing Whisper-3 in ASR accuracy and speed.
- Universal-1 trained on 12.5M hours of multilingual audio data, achieving a 13.5% accuracy improvement.
- Processes 60 minutes of audio in 38 seconds, highlighting efficiency.
- Demonstrates robustness across languages like English, Spanish, French, and German.
- The architecture includes a 600M-parameter Conformer RNN-T system for precise timestamp estimation.
- Utilizes self-supervised learning framework BEST-RQ for comprehensive training.
- Reduces hallucination rates by 30% in speech data and 90% in ambient noise.
- Enhances word-level timestamps and speaker diarization accuracy, which is crucial for various applications.
Main AI News:
In the ever-evolving realm of automatic speech recognition (ASR), AssemblyAI has once again raised the bar with its groundbreaking innovation, Universal-1. This cutting-edge model not only surpasses OpenAI’s Whisper Large-v3 models but also establishes a new standard in ASR technology, showcasing remarkable accuracy and speed.
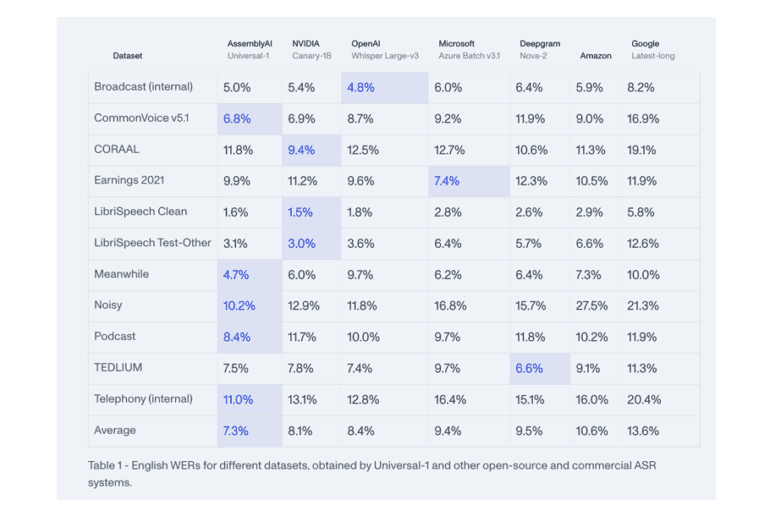
Universal-1, hailed as AssemblyAI’s most formidable speech recognition model to date, has undergone rigorous training on an extensive dataset comprising over 12.5 million hours of multilingual audio data. The outcome is unparalleled levels of precision and efficiency. When compared to its counterparts, notably the esteemed Whisper-3 from OpenAI, Universal-1 demonstrates a notable 13.5% enhancement in accuracy, accompanied by up to 30% fewer hallucinations in transcription outputs. Furthermore, it boasts an impressive capability to process 60 minutes of audio within a mere 38 seconds, underscoring its efficiency and proficiency in managing vast data volumes swiftly.
What distinguishes Universal-1 is its robustness and accuracy across diverse languages, encompassing English, Spanish, French, and German. This multilingual adeptness holds significant importance in light of the global technological landscape’s diversity and the growing demand for inclusive solutions. Universal-1’s achievement of surpassing speech-to-text accuracy by 10% or more compared to its closest competitor underscores AssemblyAI’s unwavering commitment to pushing the boundaries of speech recognition technology.
The model’s success can be attributed largely to its architectural prowess, characterized by a 600M-parameter Conformer RNN-T based system. Leveraging chunk-wise attention and a WordPiece tokenizer trained on multilingual text corpora, Universal-1 exhibits resilience across various acoustic and linguistic contexts. This design choice not only ensures precise timestamp estimation at the word level but also significantly reduces processing time for lengthy audio files.
Universal-1’s training methodology was equally comprehensive and pioneering. Employing a blend of human-transcribed and pseudo-labeled data across four languages, AssemblyAI adopted the self-supervised learning framework BEST-RQ for pre-training. This approach, prioritizing data scalability and efficient utilization of computational resources, facilitated rapid convergence during fine-tuning, enhancing both the model’s accuracy and its noise-handling capabilities.
One of Universal-1’s standout features is its remarkable ability to substantially diminish hallucination rates—by 30% in speech data and an astounding 90% in ambient noise environments. This enhancement proves invaluable for users relying on precise transcriptions across various domains, from legal and medical sectors to content creation and customer service realms.
Moreover, Universal-1 elevates the precision of word-level timestamps and speaker diarization, which is essential for applications in audio and video editing, as well as conversation analytics. With a 13% improvement in timestamp accuracy relative to its predecessor and enhancements in speaker count estimation accuracy, Universal-1 signifies significant strides in the field of speech recognition.
Conclusion:
AssemblyAI’s unveiling of Universal-1 signifies a significant leap forward in the ASR market. With unparalleled accuracy, efficiency, and multilingual capabilities, Universal-1 sets a new standard for speech recognition technology. Its advancements hold promise for diverse sectors, from legal and medical professions to content creation and customer service, indicating a transformative shift in how we interact with audio data. As competitors strive to match this level of innovation, consumers can expect a wave of improved ASR solutions that cater to their evolving needs and preferences.