
TL;DR:
- RMT, a fusion of RetNet and Transformer, is poised to redefine computer vision.
- Chinese researchers introduce explicit decay, allowing the model to leverage spatial knowledge.
- RMT optimizes token perceptual bandwidth and lowers global modeling computational costs.
- Achieves 84.1% Top1-accuracy on ImageNet-1k with just 4.5G FLOPS.
- Outperforms peers in object detection, instance segmentation, and semantic segmentation.
- Extensive tests validate RMT’s superiority.
- Contributions include Retentive Self-Attention (ReSA) and efficient computation through axis decomposition.
Main AI News:
In the ever-evolving landscape of computer vision, a groundbreaking innovation has emerged. Meet RMT, the convergence of Retentive Network (RetNet) and Transformer, promising a new era of unrivaled efficiency and accuracy. Building on the success of Transformer in natural language processing (NLP), the fusion of RetNet and Transformer brings fresh perspectives to the realm of computer vision.
Chinese researchers, recognizing the transformative potential of RetNet, embarked on a mission to integrate its principles into computer vision. The burning question: could RetNet’s prowess translate seamlessly to the visual domain? Enter RMT, the brainchild of this curiosity.
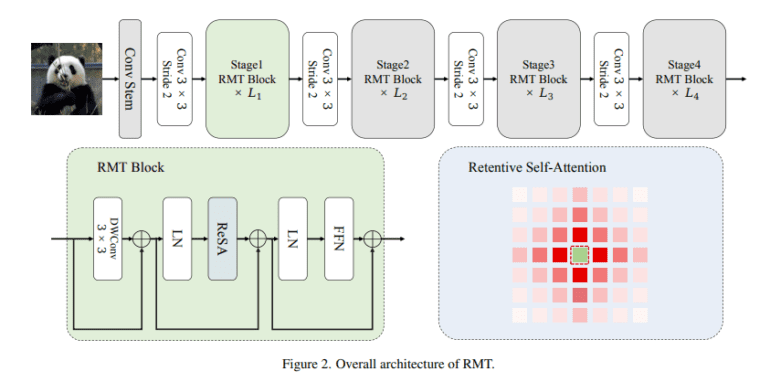
RMT, deeply influenced by RetNet, introduces a vital element to the vision backbone – explicit decay. This innovative addition empowers the vision model with the ability to leverage previously acquired knowledge about spatial distances. This distance-oriented spatial prior unlocks the capability to finely regulate the perceptual bandwidth of each token. Additionally, RMT strategically decomposes the modeling process along the image’s two coordinate axes, effectively reducing the computational demands of global modeling.
The results of extensive experiments speak volumes. RMT shines across diverse computer vision tasks, exemplified by its remarkable achievement of 84.1% Top1-accuracy on ImageNet-1k with a mere 4.5G FLOPS. When pitted against counterparts of similar size and training techniques, RMT consistently emerges as the champion in Top1-accuracy. In pivotal domains such as object detection, instance segmentation, and semantic segmentation, RMT surpasses all existing vision backbones by a wide margin.
Robust evidence underpins the efficacy of the proposed strategy. Researchers corroborate their claims with resounding success, showcasing RMT’s unparalleled prowess in image classification tasks, outperforming state-of-the-art (SOTA) models. Notably, RMT redefines the landscape of tasks like object detection and instance segmentation.
Key contributions from this endeavor include the incorporation of spatial prior knowledge into vision models, thereby adapting Retentive Network’s retention concept to a two-dimensional context, aptly named Retentive Self-Attention (ReSA). To streamline computation, researchers ingeniously decompose ReSA along two image axes, significantly reducing computational overhead while preserving model efficiency.
Conclusion:
The introduction of RMT signifies a monumental shift in the computer vision landscape. This fusion of RetNet and Transformer, backed by explicit decay and spatial knowledge utilization, not only achieves remarkable accuracy but also simplifies computational demands. RMT’s dominance across key vision tasks, from image classification to object detection, has far-reaching implications for the market, propelling it into an era of unprecedented efficiency and accuracy. Businesses and industries reliant on computer vision technologies should closely monitor the integration of RMT into their systems, as it promises a competitive edge in an increasingly data-driven world.