
TL;DR:
- Skeleton-based Human Action Recognition: Identifying human actions through skeletal joint analysis from video data using machine learning models.
- Two Main Strategies: Hand-crafted methods (outdated) and Deep learning methods (revolutionary).
- Introducing LKA-GCN: A novel “skeleton large kernel attention graph convolutional network.”
- Addressing Challenges: LKA-GCN overcomes long-range dependencies and enhances temporal information.
- Innovative Approach: Utilizes Spatiotemporal Graph Modeling, SLKA operator, and JMM strategy.
- Impressive Results: Outperforms state-of-the-art methods in various experiments.
- Market Implications: Holds promise for more accurate and robust action recognition applications.
Main AI News:
In the dynamic realm of computer vision, Skeleton-based Human Action Recognition has emerged as a transformative field, employing sophisticated algorithms to discern human actions by analyzing skeletal joint positions from video data. This cutting-edge technology harnesses the power of machine learning models to comprehend temporal dynamics and spatial configurations, leading to its wide-ranging applications in surveillance, healthcare, sports analysis, and beyond.
Over time, two principal strategies have shaped the evolution of this research domain. Firstly, the Hand-crafted methods, representing the early techniques, harnessed 3D geometric operations to construct action representations fed into classical classifiers. However, this approach relied on human assistance to learn high-level action cues, rendering it prone to outdated performance. The second, more recent strategy is the employment of Deep learning methods, which has truly revolutionized the realm of action recognition. The forefront of these methods revolves around designing feature representations that adeptly capture spatial topology and temporal motion correlations. Particularly, Graph Convolutional Networks (GCNs) have emerged as a potent solution for skeleton-based action recognition, consistently delivering impressive results in numerous studies.
In the ongoing quest for advancement, a recent article has surfaced, presenting a trailblazing approach known as the “skeleton large kernel attention graph convolutional network” (LKA-GCN). This groundbreaking methodology sets its sights on addressing two pivotal challenges that have plagued skeleton-based action recognition:
- Long-range dependencies: LKA-GCN introduces a novel skeleton large kernel attention (SLKA) operator, ingeniously capturing long-range correlations between joints, thereby surmounting the over-smoothing quandary that afflicted prior methods.
- Valuable temporal information: To bolster the temporal features and enhance recognition accuracy, the LKA-GCN cleverly incorporates a hand-crafted joint movement modeling (JMM) strategy, adeptly focusing on frames with significant joint movements.
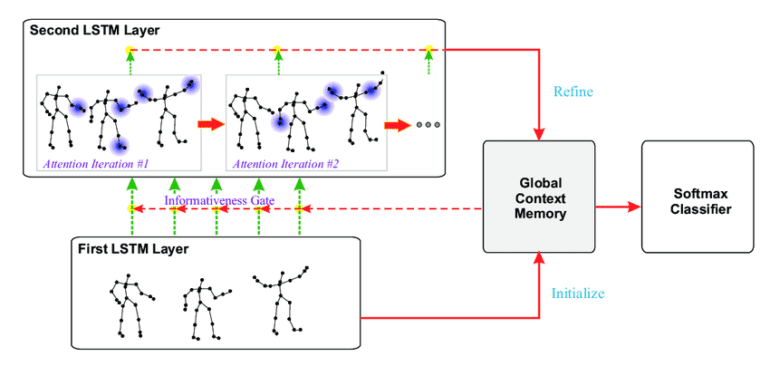
The proposed method leverages Spatiotemporal Graph Modeling to treat the skeleton data as a graph. The spatial graph deftly captures the inherent topology of human joints, while the temporal graph encodes correlations of the same joint across adjacent frames. By generating the graph representation from the sequence of 3D coordinates representing human joints over time, the LKA-GCN sets the stage for its advanced mechanisms to thrive. The SLKA operator, a key innovation, amalgamates self-attention mechanisms with large-kernel convolutions, ensuring the efficient capture of long-range dependencies among human joints. Through this, it aggregates indirect dependencies with a larger receptive field while minimizing computational overhead. Additionally, the JMM strategy plays a pivotal role in the LKA-GCN, strategically focusing on informative temporal features by calculating benchmark frames that reflect average joint movements within local ranges. The architecture of the LKA-GCN comprises spatiotemporal SLKA modules and a recognition head, skillfully employing a multi-stream fusion strategy to bolster recognition performance. This multi-stream approach artfully divides the skeleton data into three streams: joint-stream, bone-stream, and motion-stream.
To meticulously evaluate the efficacy of LKA-GCN, the authors executed various experiments, undertaking an extensive study on three prominent skeleton-based action recognition datasets: NTU-RGBD 60, NTU-RGBD 120, and Kinetics-Skeleton 400. Throughout this rigorous evaluation, the method was rigorously compared with a baseline, meticulously analyzing the impact of different components, such as the SLKA operator and Joint Movement Modeling (JMM) strategy. Furthermore, the authors delved into the exploration of a two-stream fusion strategy. The findings from these comprehensive experimental analyses paint a compelling picture, as LKA-GCN decidedly outperforms state-of-the-art methods, effectively demonstrating its prowess in capturing long-range dependencies and elevating recognition accuracy. The visual analysis further solidifies the method’s capacity to adeptly capture action semantics and joint dependencies.
Conclusion:
The introduction of LKA-GCN represents a significant breakthrough in the field of skeleton-based action recognition. By effectively capturing long-range dependencies and enhancing temporal information, this innovative approach has outperformed existing methods in experimental evaluations. Its promising results hold substantial implications for the market, as businesses in surveillance, healthcare, sports analysis, and other industries can benefit from more accurate and robust action recognition systems. Moreover, with the planned expansion to include data modalities like depth maps and point clouds, as well as optimization through knowledge distillation strategies, LKA-GCN is poised to meet the ever-increasing demands of the industrial landscape, driving further advancements and applications in virtual reality and beyond.