
TL;DR:
- Large Language Models (LLMs) excel in NLP, NLU, and NLG tasks.
- LLMs exhibit limitations like generating false content and faulty reasoning.
- Self-correction methods empower LLMs to rectify their own outputs.
- Automated feedback mechanisms reduce reliance on extensive human intervention.
- Techniques like self-training, generate-then-rank, and feedback-guided decoding enhance LLMs.
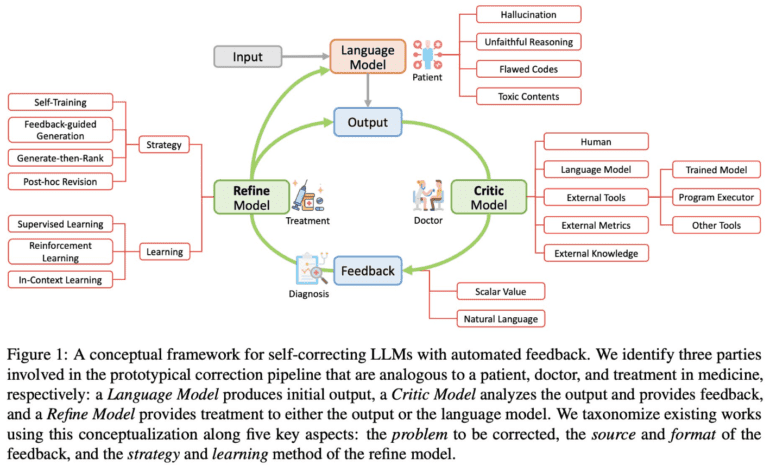
- UC Santa Barbara’s research categorizes correction approaches into training-time, generation-time, and post-hoc correction.
- Self-correction strategies find success in reasoning, code generation, and toxicity detection.
- Generation-time correction refines real-time outputs, while post-hoc correction revises already-generated content.
- These strategies pave the way for more consistent LLM behavior in real-world scenarios.
Main AI News:
In the realm of contemporary Natural Language Processing (NLP), Natural Language Understanding (NLU), and Natural Language Generation (NLG), one cannot overlook the remarkable strides achieved by large language models (LLMs) in recent times. Their accomplishments have been well-documented across diverse benchmarks, showcasing their profound aptitude for comprehending and generating human-like language. From logical reasoning to pinpointing inconsistencies and undesired behaviors, LLMs have undeniably evolved. Yet, despite their immense progress, certain limitations persist—limitations that tarnish their utility. Issues such as the creation of seemingly credible yet false content, deployment of faulty reasoning, and the generation of harmful outputs, all cast shadows on their excellence.
An avenue to surmounting these constraints lies in the concept of self-correction, where LLMs are guided to rectify their own shortcomings in information generation. Recent developments have witnessed the emergence of methodologies relying on automated feedback mechanisms, be it from the LLM itself or external systems. By reducing the reliance on extensive human intervention, these strategies hold the promise of elevating the effectiveness and practicality of LLM-powered solutions.
The self-correcting approach orchestrates the iterative learning of the model through autonomously generated feedback signals. This imbues the model with a deeper understanding of the repercussions of its actions, prompting adaptive adjustments. The wellspring of automated feedback is manifold—ranging from the LLM’s own assessment, to feedback models independent of the LLM, and external repositories such as Wikipedia or online sources. A spectrum of techniques has emerged to effectuate LLM corrections through automated feedback, encompassing self-training, generate-then-rank, feedback-guided decoding, and iterative post-hoc revision. These methodologies have showcased their efficacy across a spectrum of tasks, including logical inference, code generation, and toxicity detection.
A recent scholarly endeavor from The University of California, Santa Barbara, delves into an exhaustive exploration of this burgeoning domain of approaches. This scholarly endeavor undertakes a meticulous examination and categorization of a plethora of contemporary research initiatives leveraging these methodologies. The triad of training-time correction, generation-time correction, and post-hoc correction emerges as the cornerstone classification for these self-enhancement tactics. By infusing insights during the model’s training phase, training-time correction bolsters the model’s prowess.
This research endeavor underscores the diverse scenarios where self-correction tactics have flourished. These endeavors span a diverse gamut, from logical reasoning and code generation to toxicity detection. The study underscores the practical relevance of these strategies and their potential cross-disciplinary utility, highlighting the expansive influence these approaches wield.
The study highlights that generation-time correction refines outputs through real-time feedback signals during content creation, while post-hoc correction involves revisiting and refining previously generated content based on subsequent feedback. This taxonomic classification elucidates the nuanced mechanisms through which these techniques operate, fortifying LLM performance. As the landscape of self-enhancement methodologies evolves, opportunities for refinement and expansion emerge. By addressing these challenges and perfecting these methodologies, the horizon unfolds for LLMs and their applications to exhibit heightened consistency in real-world scenarios.
Conclusion:
The burgeoning field of self-correction approaches signifies a paradigm shift in optimizing the capabilities of large language models. By allowing LLMs to autonomously rectify their outputs, businesses can expect improved language generation that is more aligned with desired outcomes. This trend opens up opportunities for enhanced customer engagement, refined content creation, and the development of more reliable language-driven applications in various market sectors. As these strategies continue to evolve, enterprises that embrace and leverage self-correction methods stand to gain a competitive edge in delivering high-quality, coherent, and contextually accurate content, fostering better user experiences and trust in their products and services.